Author: Denis Avetisyan
New research reveals that imperfections in single-photon detectors can create vulnerabilities in quantum key distribution systems, potentially undermining their security.
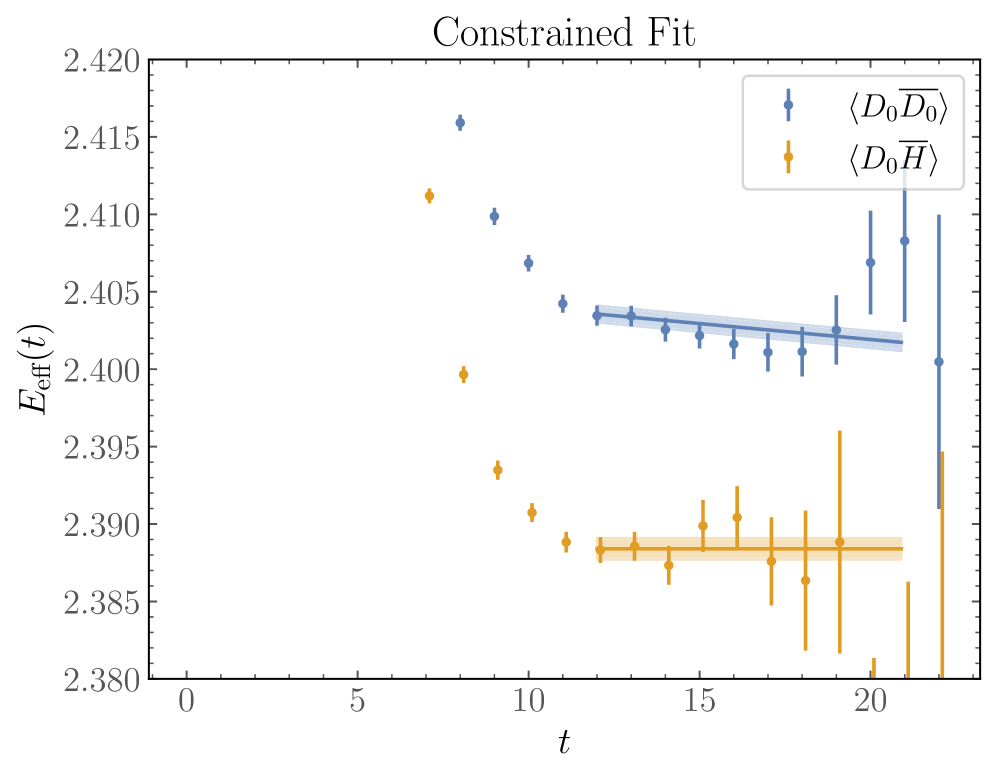
This review examines excited-state uncertainties in lattice-QCD calculations of multi-hadron systems and proposes mitigation strategies for side-channel attacks targeting practical quantum key distribution implementations.
Quantifying systematic uncertainties remains a persistent challenge in lattice quantum chromodynamics (LQCD), particularly when analyzing multi-hadron systems where accessible imaginary times limit precision. This work, ‘Excited-state uncertainties in lattice-QCD calculations of multi-hadron systems’, introduces improved gap bounds-constraints on hadron energies-to address these excited-state effects, offering tighter estimates than traditional Lanczos methods. Application to nucleon-nucleon scattering at m_π\sim 800 MeV demonstrates that these gap bounds, alongside analysis of interpolating operators, can constrain scattering amplitudes to phenomenologically relevant precision, while also revealing limitations in energy-eigenstate convergence. Do these data-driven constraints offer a pathway to more robust and reliable predictions for multi-hadron systems in QCD?
The Fundamental Challenge: Knowledge Boundaries in Language Models
Despite their remarkable ability to generate human-quality text and perform various language-based tasks, Large Language Models (LLMs) frequently encounter difficulties when confronted with problems demanding substantial external knowledge. These models excel at identifying patterns within the data they were trained on, but their understanding remains limited to this pre-existing information. Consequently, tasks requiring specific facts, nuanced contextual awareness, or the application of knowledge not explicitly present in their training data often prove challenging. While LLMs can skillfully manipulate language, they may generate plausible-sounding but factually incorrect responses when dealing with subjects beyond their immediate grasp, highlighting a critical limitation in their capacity for truly intelligent reasoning and reliable information processing.
The inherent struggle of Large Language Models with complex and commonsense reasoning significantly impacts their overall reliability. While proficient at pattern recognition and text generation, these models often falter when confronted with scenarios demanding nuanced understanding of the world and the ability to draw inferences beyond explicitly stated information. This deficiency manifests as illogical conclusions, factual inaccuracies, and an inability to navigate ambiguity – critical failings in tasks like medical diagnosis, legal argumentation, or even everyday problem-solving. Essentially, the absence of robust ‘world knowledge’ and intuitive reasoning prevents these models from consistently producing trustworthy outputs, highlighting a key limitation despite their impressive linguistic capabilities.
The effective deployment of large language models hinges on bridging the current gap in external knowledge access. While these models excel at pattern recognition and linguistic manipulation, their utility in practical applications – spanning fields like medicine, law, and scientific research – is fundamentally limited by their reliance on the data they were initially trained on. Expanding their capacity to seamlessly integrate and verify information from diverse, real-time sources isn’t simply about increasing accuracy; it’s about fostering genuine reasoning capabilities and mitigating the risk of confidently generating plausible but factually incorrect responses. Consequently, research focused on knowledge retrieval, augmented generation techniques, and robust fact-checking mechanisms represents a pivotal step towards realizing the transformative potential of LLMs and ensuring their responsible integration into critical decision-making processes.
Retrieval Augmentation: Injecting External Knowledge
Retrieval Augmented Generation (RAG) is a technique that enhances Large Language Model (LLM) performance by first retrieving relevant documents or data from an external knowledge source – such as a vector database, website, or internal document repository – and then incorporating this retrieved information into the LLM’s prompt before generating a response. This process decouples the LLM’s pre-trained parameters from the need to memorize specific facts, allowing it to dynamically access and utilize up-to-date or specialized information. The retrieval component typically employs semantic search or keyword matching to identify relevant context, and the retrieved passages are then concatenated with the user’s query to provide the LLM with a more informed basis for its response generation.
Leveraging external knowledge sources expands the effective knowledge base of Large Language Models (LLMs) beyond their pre-training data. This access to current and specific information directly improves factual consistency in generated text, as responses can be grounded in retrieved evidence rather than solely relying on potentially outdated or incomplete parameters. Consequently, supplementing LLMs with external data significantly reduces the occurrence of hallucinations – the generation of factually incorrect or nonsensical outputs – by providing a verifiable basis for response construction and enabling the LLM to differentiate between known information and areas where external validation is necessary.
Prompt engineering techniques, specifically Chain of Thought (CoT) prompting, demonstrably improve Large Language Model (LLM) performance by explicitly eliciting intermediate reasoning steps. Traditional prompting delivers a query and requests a direct answer; CoT prompting instead encourages the LLM to articulate its thought process before finalizing its response. This is achieved by including example question-answer pairs in the prompt that show the model how to break down a problem into smaller, manageable steps. Research indicates that CoT prompting significantly enhances performance on complex reasoning tasks, such as arithmetic, common sense reasoning, and symbolic manipulation, by allowing the model to better organize information and reduce errors that occur when attempting to directly map input to output.
Parameter Efficiency: A Matter of Mathematical Prudence
Adapter modules and Low-Rank Adaptation (LoRA) are parameter-efficient fine-tuning techniques that address the computational cost associated with adapting large language models (LLMs) to downstream tasks. Traditional fine-tuning updates all model parameters, requiring significant memory and processing power. In contrast, adapter modules introduce a small number of new parameters-typically fully connected layers-within the pre-trained model, while LoRA decomposes weight updates into low-rank matrices. This approach drastically reduces the number of trainable parameters – from potentially billions to just a few million – without substantially impacting performance. Consequently, these methods enable faster training, reduced storage requirements, and facilitate deployment on hardware with limited resources.
Adapter modules and Low-Rank Adaptation (LoRA) facilitate targeted knowledge integration into Large Language Models (LLMs) by introducing a limited number of trainable parameters. Rather than updating the billions of parameters within the pre-trained LLM, these techniques add or modify only a small subset, typically matrices of reduced rank. This approach significantly lowers the computational cost and memory requirements associated with fine-tuning, enabling adaptation to new tasks with fewer resources. Performance gains are achieved by focusing the learning process on task-specific information while preserving the general knowledge encoded within the original LLM weights, resulting in improved efficiency and reduced risk of catastrophic forgetting.
Parameter efficiency is increasingly critical for Large Language Model (LLM) deployment due to the substantial computational and memory requirements of these models. Resource-constrained devices, including mobile phones, embedded systems, and edge computing platforms, often lack the capacity to run full-sized LLMs. Reducing the number of trainable parameters through techniques like adapter modules or Low-Rank Adaptation (LoRA) minimizes both storage needs and computational demands during inference. This allows for on-device processing, reduced latency, and improved privacy. Furthermore, parameter efficiency is vital for scaling LLM applications; by reducing the resources required per instance, a greater number of models can be served concurrently, increasing throughput and reducing operational costs.
The Power of Minimal Supervision: Few-Shot and Zero-Shot Learning
Few-shot learning represents a paradigm shift in how large language models acquire new skills, moving away from the traditional reliance on massive, painstakingly curated datasets. Instead of requiring hundreds or thousands of examples, these models can achieve impressive performance with just a few – sometimes even a single – demonstration. This capability stems from the model’s pre-training on vast amounts of text, which equips it with a broad understanding of language and concepts; the limited examples then serve as a guide to apply this existing knowledge to a novel task. Essentially, the model learns to learn from minimal data, mirroring a key aspect of human intelligence and dramatically reducing the cost and effort associated with adapting LLMs to specific applications. This efficiency opens doors to deploying these powerful tools in resource-constrained environments and tackling specialized tasks where extensive labeled data is simply unavailable.
Zero-shot learning represents a remarkable advancement in artificial intelligence, enabling large language models to perform tasks without any prior task-specific training data. Instead of requiring labeled examples, these models leverage their pre-existing knowledge-acquired during extensive training on massive datasets-to understand and execute novel instructions. This generalization isn’t simply about recognizing patterns; it involves a degree of conceptual understanding, allowing the model to infer the desired outcome from the task description itself. For instance, a model trained on general language understanding could, with proper prompting, translate a language it has never encountered or summarize a document on a completely unfamiliar topic. This capacity dramatically expands the applicability of LLMs, moving beyond predefined tasks and towards more flexible, human-like problem-solving.
The adaptability of large language models to novel situations represents a significant leap in artificial intelligence, largely due to their capacity for few-shot and zero-shot learning. This isn’t simply about reducing the demand for labeled data-it’s about enabling LLMs to function effectively in environments they haven’t encountered during training. Consider specialized fields like medical diagnosis or legal analysis, where acquiring extensive datasets is both costly and time-consuming; these learning techniques allow models to rapidly assimilate new information and perform tasks with limited examples. Moreover, the ability to address previously unseen problems unlocks potential applications in rapidly evolving domains, such as responding to emerging crises or analyzing entirely new types of data, fostering a level of flexibility previously unattainable in AI systems.
The pursuit of secure communication, as detailed in the study of vulnerabilities within Quantum Key Distribution systems, demands an uncompromising adherence to foundational principles. Imperfections in single-photon detectors introduce avenues for side-channel attacks, threatening the integrity of the cryptographic exchange. This echoes Jean-Jacques Rousseau’s sentiment: “The best way to learn is to question everything.” The paper rigorously questions the assumed security of current QKD implementations, dissecting potential weaknesses with mathematical precision. The focus isn’t merely on achieving functional security, but on proving it-a commitment to a demonstrable truth, mirroring the elegance of a provable algorithm over one that simply appears to function correctly. Such meticulousness is paramount when dealing with the delicate balance between theoretical security and practical implementation.
The Horizon Beckons
The pursuit of provable security, as illuminated by this work, exposes a fundamental tension. While theoretical Quantum Key Distribution offers elegant mathematical guarantees, its instantiation in physical devices introduces a regrettable messiness. The demonstrated vulnerabilities are not merely engineering hiccups; they are manifestations of the inherent difficulty in mapping a perfect abstraction onto an imperfect reality. Future effort must address not simply detection of these side-channel attacks, but the development of device-independent protocols that sidestep the need for absolute trust in component integrity – a truly symmetrical solution.
One anticipates a shift in emphasis. The focus will likely move beyond simply improving detector efficiency-a pursuit of diminishing returns-and towards architectures that actively verify device behavior. Perhaps entanglement-based schemes, though computationally demanding, offer a path toward self-certifying systems. The challenge lies in extracting meaningful security proofs from inherently noisy measurements – establishing a lower bound on fidelity that is both rigorous and practical.
Ultimately, the field will be judged not by the complexity of its cryptographic algorithms, but by the simplicity-the elegance-of its physical implementations. A truly secure system will be one that requires no assumptions, relies on no hidden variables, and yields its secrets only to those who can demonstrate an understanding of its underlying mathematical harmony.
Original article: https://arxiv.org/pdf/2601.22272.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- What Song Is In The New Supergirl Trailer (& What It Means For The DC Movie)
- Highly Anticipated Strategy RPG Finally Sets Release Date (And It’s Soon)
- Dune 3 Gets the Huge Update Fans Have Been Waiting For
- TV legend Carol Kirkwood reveals the reasons why she decided to retire after 28 years with BBC
- Crimson Desert is a “Cynical Amalgamation of Borrowed Mechanics,” Says Larian’s Publishing Director
- 49 Years Ago Today, Movie History Was Changed by a Film You’ve Never Even Seen
- Jaleco Sports: Bases Loaded II announced for PS5, Switch; now available
- Digimon Is Getting a New RPG in 2026 (And You Probably Missed It)
- Kanye West’s Wife Bianca Censori Details New Marriage Milestone
- Beyond the Horizon: Unveiling the Holographic Universe
2026-02-02 22:48