Author: Denis Avetisyan
A new approach unifies curiosity-driven learning with goal-directed optimization, enabling agents to both acquire knowledge and actively pursue objectives.
This review introduces ‘pragmatic curiosity,’ a hybrid learning-optimization paradigm built on active inference, combining Bayesian optimization and experimental design.
Many engineering and scientific workflows struggle to simultaneously optimize performance and reduce uncertainty when evaluating complex, black-box systems. This paper introduces ‘Pragmatic Curiosity: A Hybrid Learning-Optimization Paradigm via Active Inference,’ a novel framework unifying Bayesian optimization and Bayesian experimental design under the principles of active inference. By minimizing expected free energy-a single objective that balances pragmatic utility with information gain-pragmatic curiosity consistently outperforms existing methods across tasks ranging from system identification to preference learning. Could this approach unlock more efficient and robust decision-making in scenarios demanding both knowledge acquisition and goal achievement?
The Illusion of Efficiency: Why Optimization Always Hurts
The pursuit of optimal solutions in numerous real-world applications, ranging from drug discovery and materials science to engineering design and financial modeling, is frequently hampered by the computational cost of evaluating potential candidates. Each assessment of a proposed solution – determining its ‘fitness’ or performance – can require significant resources, time, or even physical experimentation. This reality necessitates a focus on sample efficiency – the ability to achieve good results with a minimal number of evaluations. Unlike algorithms that can afford to test millions of possibilities, those tackling expensive objective functions must intelligently select which solutions to evaluate, prioritizing informative tests over exhaustive searches. Consequently, strategies that maximize the knowledge gained from each evaluation become paramount, shifting the emphasis from sheer computational power to clever algorithmic design and efficient data utilization.
Optimization problems involving numerous variables-often termed high-dimensional search spaces-present a significant hurdle for conventional algorithms. As the number of dimensions increases, the volume of the search space grows exponentially, effectively scattering potential solutions and making exhaustive searches impractical. Consequently, traditional methods, like grid search or random sampling, require an impractically large number of evaluations to locate optimal or even near-optimal solutions. This leads to slow convergence, where the algorithm takes a prohibitively long time to settle on a good solution, and frequently results in suboptimal outcomes – solutions that are acceptable, but far from the best possible given the problem’s constraints. The curse of dimensionality, as it’s known, underscores the need for more intelligent search strategies capable of navigating these complex landscapes efficiently.
The pursuit of optimal solutions in complex systems often hinges on a delicate balance between exploration and exploitation. Algorithms must continually decide whether to investigate novel areas of the search space – potentially uncovering significantly better outcomes – or to focus on improving existing, already-promising solutions. This isn’t merely a question of allocating resources; it’s a fundamental trade-off. Overemphasis on exploitation can lead to premature convergence on local optima, hindering the discovery of truly global solutions. Conversely, excessive exploration without sufficient exploitation risks wasting computational effort on areas unlikely to yield substantial improvements. Effective algorithms dynamically adjust this balance, prioritizing exploration when uncertainty is high and shifting towards exploitation as confidence in promising regions grows, ultimately driving efficient and robust optimization.
Active Inference: A Theory Built on Wishful Thinking
Active Inference posits that all behavior can be understood as an iterative process of inference, where agents actively sample the world to test hypotheses about its causes. This framework utilizes the principle of minimizing \text{EFE} = D_{KL}(Q(z|o) || P(z|o)) - \mathbb{E}_{Q(z|o)}[\log P(o|z)] , where D_{KL} represents the Kullback-Leibler divergence, Q(z|o) is the approximate posterior belief about hidden states z given observations o, and P(z|o) and P(o|z) define a generative model encoding prior beliefs and observational likelihoods, respectively. Minimizing EFE, therefore, involves both reducing the surprisal of sensory input (accuracy) and reducing uncertainty about the causes of that input (complexity), driving agents to actively seek out information that resolves mismatches between predictions and reality.
Pragmatic Curiosity builds upon Active Inference by integrating two distinct motivational drives: epistemic and pragmatic. Epistemic motivation centers on minimizing uncertainty and maximizing information gain about the environment, irrespective of specific goals. Pragmatic motivation, conversely, is directed towards achieving desired outcomes or maintaining internal states; it prioritizes information that reduces uncertainty about how to reach those goals. This dual-drive system means that behavior isn’t solely focused on reducing overall surprise \text{EFE}, but rather on selectively seeking information that is both informative and relevant to fulfilling predefined objectives, effectively balancing exploration with exploitation.
Pragmatic Curiosity, operating within the Active Inference framework, actively seeks information by minimizing Expected Free Energy (EFE). This minimization isn’t solely driven by reducing uncertainty; it integrates both epistemic and pragmatic value. Specifically, the system prioritizes information that not only reduces the discrepancy between its predictions and sensory input – increasing knowledge – but also contributes to achieving pre-defined goals. This means actions are selected to resolve both predictive errors and to bring about desired states, effectively balancing information gain with goal-directed behavior. The resulting behavior is therefore a function of both reducing uncertainty about the world and actively shaping the world to fulfill objectives, leading to efficient exploration and adaptive responses.
Surrogate Models: A Necessary Evil
Pragmatic Curiosity employs surrogate models to mitigate the computational expense associated with directly evaluating the true objective function. These surrogate models function as efficient approximations, allowing the algorithm to predict the outcome of a given input without requiring a full evaluation of the potentially complex and time-consuming original function. This is particularly valuable in optimization problems where numerous evaluations are necessary to locate the optimal solution; by initially utilizing the surrogate model, the number of costly true function evaluations can be substantially reduced, accelerating the optimization process and enabling efficient exploration of the search space.
Gaussian Processes (GPs) function as surrogate models by defining a probability distribution over possible functions, enabling both prediction and uncertainty quantification. Unlike deterministic models, GPs output a mean prediction and a variance, reflecting the confidence in that prediction. This is achieved by assuming any finite set of function values follows a multivariate Gaussian distribution. The kernel function, a key component of GPs, defines the similarity between data points and influences the smoothness and behavior of the predicted function. This probabilistic framework allows Pragmatic Curiosity to not only estimate the objective function but also to strategically balance exploration and exploitation by prioritizing regions with high uncertainty, leading to more efficient optimization.
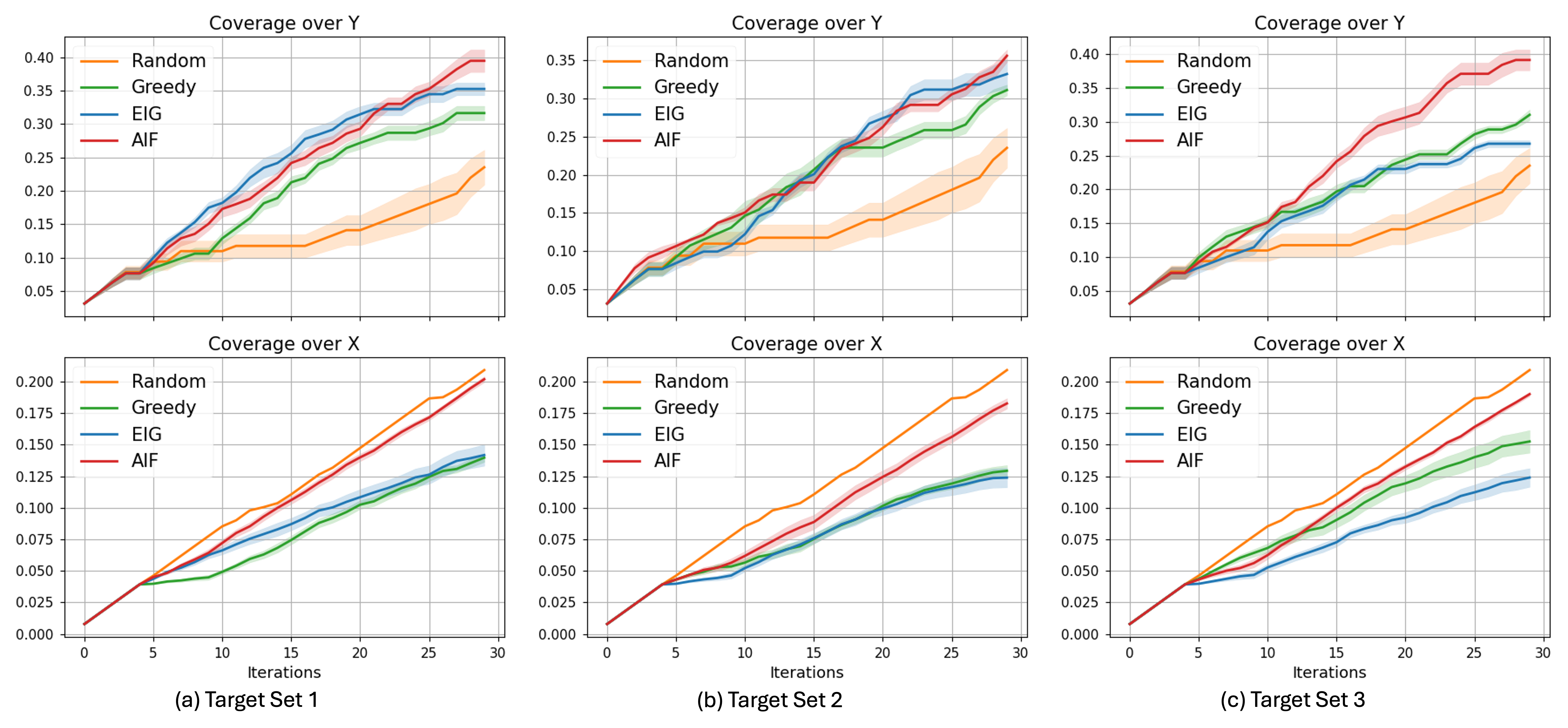
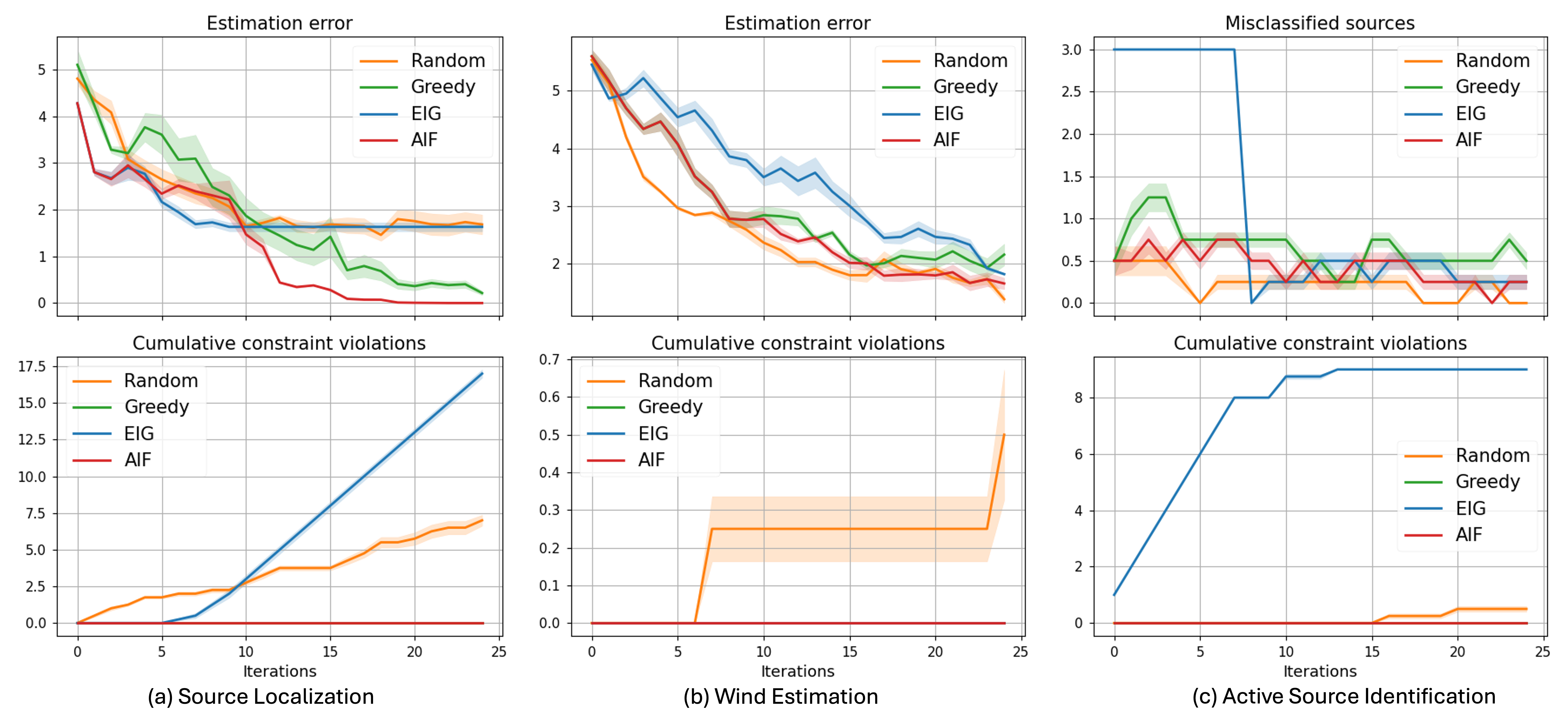
Iterative refinement of the surrogate model is central to reducing computational cost in optimization tasks. This process involves updating the surrogate model with each new evaluation of the true objective function, thereby improving its accuracy and predictive capability. Utilizing this refined surrogate to guide exploration – specifically, selecting points for evaluation that maximize information gain or expected improvement – allows Pragmatic Curiosity to converge on optimal solutions with significantly fewer expensive function evaluations. In constrained system identification tasks, this approach has demonstrated a reduction of 40% in the number of queries required to achieve near-perfect estimation accuracy compared to alternative optimization methods.
The Illusion of Impact: Why This Might Actually Matter (Sometimes)
Pragmatic Curiosity offers a powerful solution to the challenges inherent in constrained system identification, a critical process across numerous engineering disciplines. Traditional methods often struggle when operating within strict operational boundaries, potentially leading to unsafe or infeasible solutions. This approach, however, prioritizes exploration that directly addresses these constraints, actively seeking data that clarifies the feasible region of operation. By intelligently balancing the desire to learn the system’s behavior with the necessity of respecting pre-defined limitations, Pragmatic Curiosity avoids wasting resources on exploration that violates those boundaries. This focused approach not only enhances the efficiency of the identification process but also ensures the resulting model is immediately deployable within the intended operational context, offering a significant advantage in real-world applications where safety and feasibility are paramount.
A significant benefit of Pragmatic Curiosity lies in its ability to refine active search strategies, achieving a demonstrably higher yield of critical failure region discovery with fixed computational resources. Conventional active learning methods often explore broadly, potentially wasting valuable search iterations on irrelevant areas of the parameter space. This approach, however, prioritizes exploration guided by a learned model of constraint satisfaction, allowing it to pinpoint and investigate regions most likely to reveal system vulnerabilities. Studies indicate that, within the same budgetary constraints-meaning the same number of simulations or experiments-Pragmatic Curiosity can identify approximately 10% more of the critical failure region compared to standard methods. This improved efficiency is particularly crucial in high-stakes applications, such as robotics and aerospace engineering, where identifying potential failure modes proactively can prevent costly and dangerous incidents.
This innovative methodology extends beyond traditional optimization challenges to successfully navigate composite Bayesian optimization, a realm often complicated by subjective and evolving user preferences. In scenarios where discerning the true underlying objective is difficult, this approach consistently achieves learning, a feat that has proven elusive for competing baseline algorithms. The system’s ability to adapt and refine its understanding, even with incomplete or ambiguous feedback, suggests a powerful tool for personalized systems and user-centric design – effectively bridging the gap between algorithmic efficiency and human subjectivity. This consistent success rate highlights the potential for creating more intuitive and responsive technologies tailored to individual needs and preferences.
The Inevitable Failure: A Realistic Outlook
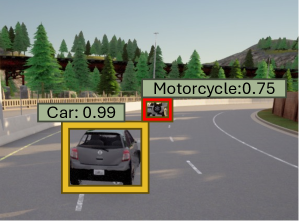
Automated failure discovery in AI simulations is increasingly leveraging the strengths of computer vision and natural language processing techniques. Researchers are integrating systems like YOLO – typically used for real-time object detection in images and video – with Large Language Model (LLM) evaluation metrics to monitor simulated environments. This combined approach allows for the identification of anomalous behaviors or unexpected states that might indicate a potential failure. For example, YOLO can track the position and orientation of virtual agents or objects, while LLM evaluation can assess the coherence and safety of their actions or generated text. By correlating these observations, the system can flag scenarios where an AI system deviates from expected performance, providing a proactive method for enhancing robustness and safety before deployment in real-world applications.
The development of truly reliable and safe artificial intelligence hinges on a proactive understanding of potential failure scenarios. Rather than reacting to errors as they occur, a robust AI system necessitates the deliberate identification of circumstances under which performance might degrade or completely fail. This isn’t simply about anticipating known issues; it demands exploring edge cases, unusual inputs, and unforeseen combinations of factors that could expose vulnerabilities. By systematically probing for weaknesses – through methods like adversarial testing and simulations – developers can build systems capable of gracefully handling unexpected situations, ensuring consistent and predictable behavior even when confronted with challenging or novel inputs. Ultimately, prioritizing failure identification isn’t about acknowledging limitations, but about actively building resilience into the core design of AI, fostering trust and enabling deployment in critical applications.
Anticipating potential weaknesses within artificial intelligence systems is paramount to building applications that are not only effective but also dependable and safe. Rather than reacting to failures after they occur, a proactive approach – systematically identifying and mitigating possible error scenarios – significantly enhances an AI’s resilience. This foresight allows developers to fortify algorithms against unexpected inputs, edge cases, and adversarial attacks, leading to more consistent performance across diverse conditions. Ultimately, addressing vulnerabilities before deployment fosters greater user confidence and enables the responsible integration of AI into critical domains, from autonomous vehicles to healthcare diagnostics, where reliability is non-negotiable.
The pursuit of elegant, all-encompassing frameworks often obscures a simple truth: systems degrade. This paper’s ‘pragmatic curiosity’ – a unification of Bayesian optimization and active inference – feels less like a solution and more like a sophisticated accounting of inevitable entropy. As Robert Tarjan observed, “Code is like humor. If you have to explain it, it’s not very good.” This work doesn’t promise to solve the exploration-exploitation dilemma inherent in hybrid learning; it merely offers a more nuanced way to manage it, acknowledging that even the most carefully constructed acquisition functions will eventually succumb to the pressures of production. The focus on balancing information gain with goal-directed behavior is a pragmatic acceptance of limitations, a tacit admission that perfect knowledge is an illusion.
What’s Next?
The synthesis of Bayesian optimization and active inference, as presented, offers a predictably elegant solution. It will, of course, encounter the usual resistance from reality. The framework hinges on accurately modeling ‘pragmatic curiosity’ – a tidy concept, but one likely to dissolve into a mess of proxy rewards and ill-defined preferences the moment it leaves the simulation. The real challenge isn’t the mathematics, but the inevitable feature creep. Each added constraint, each attempt to account for ‘real-world’ noise, introduces another layer of abstraction, another potential point of failure.
Future work will undoubtedly focus on scalability – a familiar refrain. More parameters, larger state spaces, and the perpetual need to reduce computational cost. But a more interesting, and likely neglected, area lies in understanding the limits of this approach. What classes of problems cannot be effectively addressed by maximizing information gain while simultaneously pursuing goals? It is a safe bet that those problems will prove far more common than the textbook examples.
The promise of a unified learning-optimization paradigm is appealing, but remember: anything that promises to simplify life adds another layer of abstraction. Documentation is a myth invented by managers. The true test will not be the framework’s theoretical elegance, but its ability to survive the slow, grinding process of being deployed and inevitably patched in production. CI is the temple – one prays nothing breaks.
Original article: https://arxiv.org/pdf/2602.06104.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Surprise Isekai Anime Confirms Season 2 With New Crunchyroll Streaming Release
- The Super Mario Galaxy Movie: 50 Easter Eggs, References & Major Cameos Explained
- Starfield (PS5) Review – A Successful Cross-Console Voyage
- 10 Best Free Games on Steam in 2026, Ranked
- All 7 New Supes In The Boys Season 5 & Their Powers Explained
- Preview: Sword Art Online Returns to PS5 as a Darker Open World Action RPG This Summer
- ‘Project Hail Mary’: The Biggest Differences From the Book, Explained
- Skate 4 – Manny Go Round Goals Guide | All of the Above Sequence
- Frieren: Beyond Journey’s End Gets a New Release After Season 2 Finale
- Sydney Sweeney’s The Housemaid 2 Sets Streaming Release Date
2026-02-09 12:54