Author: Denis Avetisyan
New research reveals a critical gap in the ability of current artificial intelligence systems to solve complex problems that require long-term planning and adapting to novel situations.

OdysseyArena, a new benchmark for agent evaluation, demonstrates that large language models still lag significantly behind human performance in inductive reasoning and active problem-solving within interactive environments.
While large language models have spurred progress in autonomous agents, current evaluations largely overlook the crucial ability to learn complex environments through experience-a cornerstone of sustained, strategic behavior. To address this, we introduce ‘OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions’, a suite of interactive environments designed to rigorously assess an agent’s capacity for inductive reasoning and long-horizon planning. Our results, obtained from evaluating 15+ leading LLMs, reveal a significant deficiency in inductive capabilities, even among frontier models, highlighting a critical bottleneck in achieving truly autonomous discovery. Can we develop more robust and adaptive agents capable of navigating complex, dynamic environments through genuine learning and foresight?
The Challenge of Prolonged Cognitive Sequences
Conventional artificial intelligence systems frequently encounter difficulties when tasked with problems demanding prolonged, sequential thought. Unlike human cognition, these agents often struggle to maintain a coherent line of reasoning over numerous steps, instead becoming trapped in unproductive cycles of action and reaction. This limitation stems from a reliance on immediate rewards and a difficulty in anticipating the long-term consequences of present decisions. Consequently, tasks requiring strategic foresight-such as navigating complex games or managing dynamic resources-prove exceptionally challenging, as the systems fail to effectively plan beyond the immediate future and exhibit a marked inability to learn from past errors in extended sequences.
Effective navigation of intricate and ever-changing environments necessitates more than simply responding to immediate stimuli; it demands a capacity for proactive exploration and strategic foresight. Rather than merely reacting to what is, a truly adaptable agent must anticipate potential future states and formulate plans accordingly. This involves not just processing sensory information, but also building internal models of the environment, simulating possible outcomes of different actions, and selecting those that maximize long-term goals. Such anticipatory behavior allows for preemptive problem-solving, efficient resource allocation, and the ability to capitalize on emerging opportunities – ultimately distinguishing successful agents from those limited to purely reactive loops.
Existing artificial intelligence systems demonstrate a limited capacity for generalization in long-term planning, frequently excelling in narrowly defined situations but faltering when confronted with even slight variations in the environment or task parameters. This fragility stems from a reliance on memorized patterns rather than a robust understanding of underlying principles, causing performance to degrade rapidly as complexity increases. Studies reveal that these agents struggle to adapt learned strategies to novel circumstances, often requiring extensive retraining for each new challenge. Consequently, a significant gap remains between current capabilities and the demands of real-world applications requiring adaptable, long-horizon reasoning – a crucial impediment to deploying AI in dynamic, unpredictable settings.
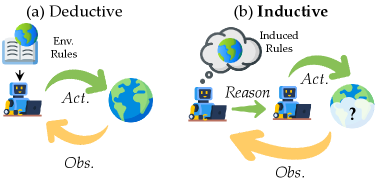
OdysseyArena: A Rigorous Testbed for Cognitive Agents
OdysseyArena is a platform comprising multiple interactive environments specifically engineered to assess agent performance in complex cognitive tasks. These environments demand long-horizon reasoning, requiring agents to plan and execute strategies over extended time scales; active learning, where agents must strategically gather information through interaction; and inductive reasoning, necessitating the generalization of learned patterns to novel situations. The platform facilitates evaluation of an agent’s ability to not only react to immediate stimuli, but to proactively explore, hypothesize, and adapt its behavior based on accumulated experience within the given environment.
OdysseyArena environments incorporate a range of dynamic complexities to assess agent adaptability. Discrete latent rules govern environments where underlying states transition based on defined, but potentially unobservable, conditions. Continuous stochastic dynamics introduce probabilistic elements to state transitions, requiring agents to operate under uncertainty. Furthermore, the framework includes environments exhibiting periodic temporal patterns, demanding agents learn and predict recurring events. These diverse dynamics – discrete, continuous stochastic, and periodic – are combined and varied across environments to provide a comprehensive evaluation of agent reasoning and planning capabilities in non-static scenarios.
OdysseyArena offers two distinct evaluation tiers: OdysseyArena-Lite and OdysseyArena-Challenge. OdysseyArena-Lite is designed for rapid and standardized agent assessment, providing a baseline performance metric. In contrast, OdysseyArena-Challenge presents significantly more complex scenarios and imposes step limits exceeding 1000 steps per environment. This extended interaction requirement is specifically intended to evaluate an agent’s ability to maintain consistent reasoning and problem-solving capabilities over prolonged periods, thereby probing the stability of its inductive and long-horizon reasoning skills.
As of the current evaluation period, Gemini 3 Pro Preview has achieved a success rate of 44.17% on the OdysseyArena platform, representing the highest documented performance to date. This result was obtained through testing across the suite’s diverse environments, which include tasks requiring long-horizon planning, active exploration, and inductive reasoning. The 44.17% success rate serves as a quantitative benchmark for evaluating the capabilities of other agents and models on complex, interactive tasks, and establishes a current state-of-the-art baseline for future research and development in the field of artificial intelligence.
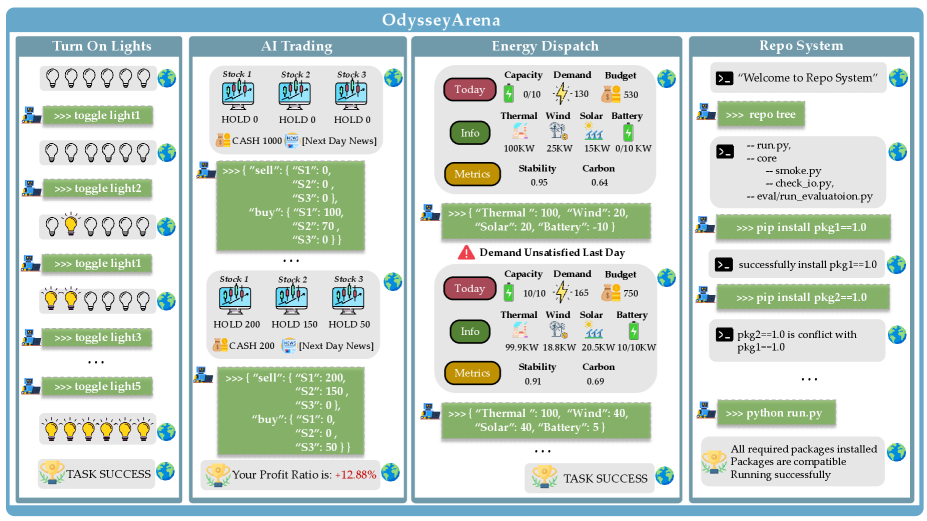
Deconstructing Complexity: The Underlying Dynamics of the Environments
The ‘Turn On Lights’ environment presents a challenge based on the inference of hidden Boolean logic. Agents are not directly provided with the rules governing light state changes; instead, they must deduce these rules through observation and interaction. Each light switch operates as a binary variable, and the goal state is achieved only when all lights conform to a specific, but initially unknown, Boolean expression. This necessitates agents employing strategies to identify the underlying logical relationships-typically AND, OR, or XOR combinations-between switch states and desired light configurations. Successful agents must therefore effectively perform a form of symbolic reasoning to map actions to outcomes and ultimately control the environment.
The ‘AI Trading’ environment models a financial market characterized by continuous stochastic dynamics, meaning asset prices evolve randomly over time. This necessitates agents develop strategies for managing financial risk and operating under uncertainty; unlike discrete environments, actions do not have immediately predictable outcomes. The simulation incorporates features such as transaction costs, price impact, and varying market volatility to create a realistic, albeit simplified, trading landscape. Agents are evaluated on their ability to maximize returns while accounting for these dynamic and unpredictable market conditions, requiring them to learn and adapt to changing price distributions and correlations.
The ‘Energy Dispatch’ environment models electricity grid operations characterized by predictable, recurring demand patterns. These patterns, often daily or weekly cycles, dictate resource requirements, forcing agents to learn and exploit temporal dependencies for efficient dispatch. Specifically, the environment presents agents with fluctuating energy demands that repeat over time, necessitating predictive strategies to pre-allocate resources and minimize costs associated with insufficient supply or over-provisioning. Successful agents must therefore develop mechanisms to anticipate these cyclical needs and proactively adjust resource allocation, rather than reacting solely to immediate requests.
The ‘Repo System’ environment models software package management through a relational graph structure, where nodes represent packages and edges denote dependencies between them. This means a package may require other packages to function correctly, creating a network of interconnected components. Agents interacting with this environment must navigate these dependencies to successfully install, upgrade, or remove packages without breaking the system. The environment accurately reflects real-world package managers like apt, yum, or npm, where resolving dependencies is crucial for maintaining system stability and functionality. Consequently, agents are challenged with tasks such as dependency resolution, conflict detection, and efficient package selection within a complex, interconnected graph.
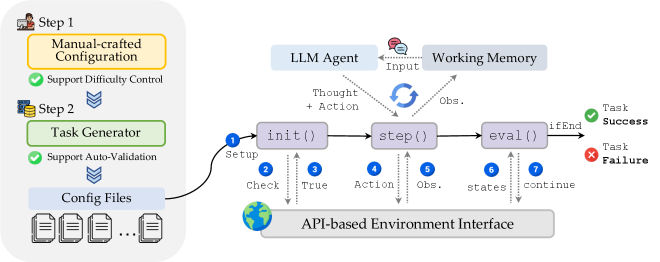
LLM Agents: A Proving Ground for Long-Horizon Cognitive Capabilities
Large Language Model (LLM) Agents provide a uniquely versatile platform for investigating the complexities of long-horizon reasoning, particularly within the challenging environment of OdysseyArena. These agents, powered by advanced language processing capabilities, aren’t simply programmed with solutions; instead, they actively explore the game world, formulate strategies, and learn from experience. This dynamic approach allows researchers to observe how an artificial intelligence tackles problems that require planning and adaptation over extended sequences of actions-a critical aspect of general intelligence. By utilizing LLM Agents, scientists can dissect the cognitive processes involved in inductive reasoning and problem-solving, gaining insights into how these agents overcome obstacles and ultimately achieve their objectives in a complex, evolving landscape. The arena serves as a controlled, yet demanding, proving ground for these capabilities, enabling detailed analysis of agent behavior and the development of more robust and adaptable AI systems.
Large Language Model (LLM) Agents exhibit a remarkable ability to not only actively explore unfamiliar environments but also to leverage inductive reasoning – forming generalizations from specific instances – which proves essential for navigating complex challenges. This combination allows the agents to move beyond simple memorization of successful actions and instead develop a flexible understanding of the environment’s underlying principles. Through exploration, they gather data, and then, crucially, they apply inductive reasoning to predict the outcomes of different actions, enabling them to formulate strategies for achieving long-term goals. This capacity is particularly valuable in scenarios requiring adaptation and problem-solving, where pre-programmed responses are insufficient, and the agents must learn and generalize from experience to overcome obstacles and efficiently reach their objectives.
The efficacy of Large Language Model (LLM) Agents within complex environments, such as OdysseyArena, is inextricably linked to the crafting of their Reward Function. This function serves as the primary mechanism through which the agent learns and adapts, effectively shaping its behavior by assigning values to different actions and states. A well-designed Reward Function not only incentivizes progress towards the ultimate goal but also discourages unproductive behaviors, like repetitive action loops. Conversely, a poorly defined function can lead to unintended consequences, where the agent optimizes for a local reward without achieving the broader objective, or gets stuck in suboptimal strategies. Therefore, meticulous attention to the Reward Function’s structure and parameters is paramount for successfully harnessing the potential of LLM Agents in long-horizon reasoning tasks; it dictates what the agent perceives as success and, consequently, how it navigates the complexities of the environment.
A key aspect of evaluating LLM Agent performance within complex environments lies in scrutinizing their behavioral patterns, particularly their capacity to escape repetitive cycles. Researchers quantify this with the Loop Ratio metric, which measures the frequency with which an agent revisits previously explored states or actions without achieving meaningful progress. A low Loop Ratio indicates effective problem-solving and a robust ability to overcome challenges, suggesting the agent is successfully generalizing from experience and adapting its strategy. Conversely, a high Loop Ratio signals a failure to learn from past attempts, often resulting in the agent becoming trapped in unproductive action sequences and hindering its ability to solve long-horizon inductive reasoning tasks – effectively demonstrating a lack of true understanding of the environment and its dynamics.
A consistently high Loop Ratio within an LLM agent signifies a critical impediment to successful long-horizon reasoning. This metric quantifies the tendency of an agent to repeat sequences of actions without progressing toward a solution, effectively trapping it in unproductive cycles. While exploration is valuable, excessive repetition indicates a failure to generalize learned information or adapt to novel situations within the complex environment. Consequently, an agent exhibiting a high Loop Ratio struggles to overcome challenges requiring inductive reasoning – the ability to identify patterns and apply them to new, unseen scenarios – ultimately hindering its capacity to achieve long-term goals and solve intricate tasks within OdysseyArena.
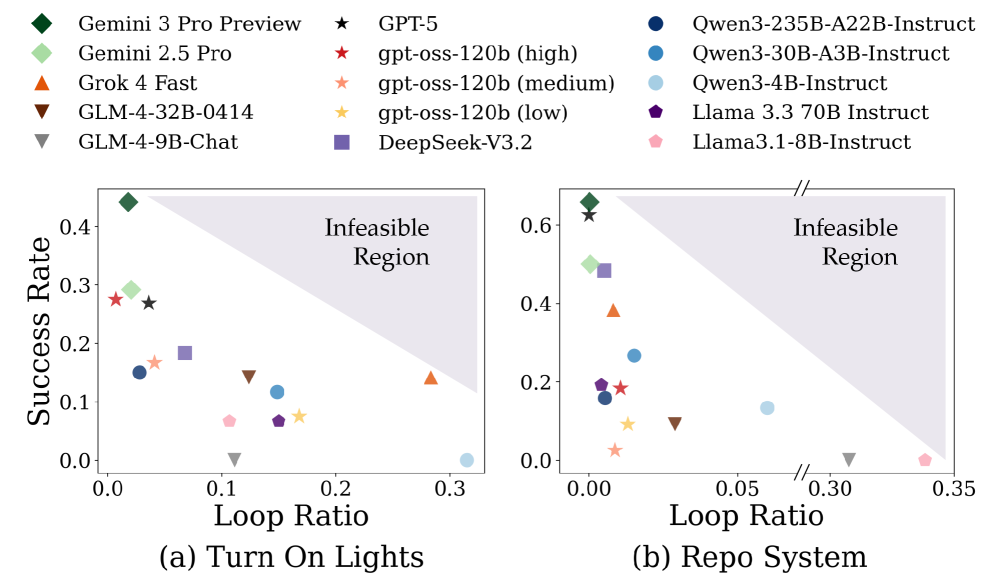
The pursuit of robust AI agents, as highlighted by OdysseyArena, demands a focus on provable correctness rather than merely demonstrable function. Current Large Language Models, while adept at pattern recognition, struggle with the inductive reasoning required for long-horizon interactions within complex environments. This aligns with a fundamental principle of computational elegance: a solution’s validity stems from its logical completeness, not just its success on limited test cases. As Barbara Liskov stated, “It’s one thing to program something to work, but quite another to have a program that’s elegant and understandable.” OdysseyArena serves as a rigorous benchmark, revealing the need for AI systems built upon provable foundations, moving beyond empirical success towards true computational purity.
What’s Next?
The introduction of OdysseyArena exposes, with a certain elegant clarity, what was already suspected: current large language models, despite their impressive capacity for mimicking human text, remain fundamentally deficient in genuine inductive reasoning. The environments presented are not merely challenging; they demand a level of causal understanding and flexible problem-solving that transcends statistical pattern matching. The observed performance gap is not a matter of scaling existing architectures, but a failure of foundational principles. The pursuit of ‘bigger’ models, without a corresponding focus on provable reasoning mechanisms, appears increasingly… optimistic.
Future work must prioritize the development of agents grounded in formal logic. Environments like OdysseyArena should serve not as benchmarks for bragging rights, but as rigorous testbeds for verifying the correctness of implemented reasoning systems. The emphasis should shift from achieving high scores on aggregate metrics to demonstrating provable guarantees of solution validity. To claim progress, a system must not simply act intelligently; it must demonstrate its intelligence through verifiable proofs.
Ultimately, the true measure of success will not be whether an agent can navigate a complex environment, but whether its actions are derived from a logically sound and mathematically verifiable foundation. Until then, the current excitement surrounding large language models risks being little more than a sophisticated illusion – a dazzling display of complexity built on a surprisingly fragile base.
Original article: https://arxiv.org/pdf/2602.05843.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Super Mario Galaxy Movie: 50 Easter Eggs, References & Major Cameos Explained
- 10 Best Free Games on Steam in 2026, Ranked
- Surprise Isekai Anime Confirms Season 2 With New Crunchyroll Streaming Release
- ‘Project Hail Mary’: The Biggest Differences From the Book, Explained
- Skate 4 – Manny Go Round Goals Guide | All of the Above Sequence
- Starfield (PS5) Review – A Successful Cross-Console Voyage
- Preview: Sword Art Online Returns to PS5 as a Darker Open World Action RPG This Summer
- Sydney Sweeney’s The Housemaid 2 Sets Streaming Release Date
- Why is Tech Jacket gender-swapped in Invincible season 4 and who voices her?
- Coronation Street airs horrifying discovery for Summer Spellman about villainous Theo in early ITVX release
2026-02-08 20:01