Author: Denis Avetisyan
A new approach combines search algorithms with experience replay to enable large language models to continuously refine their problem-solving skills without retraining.
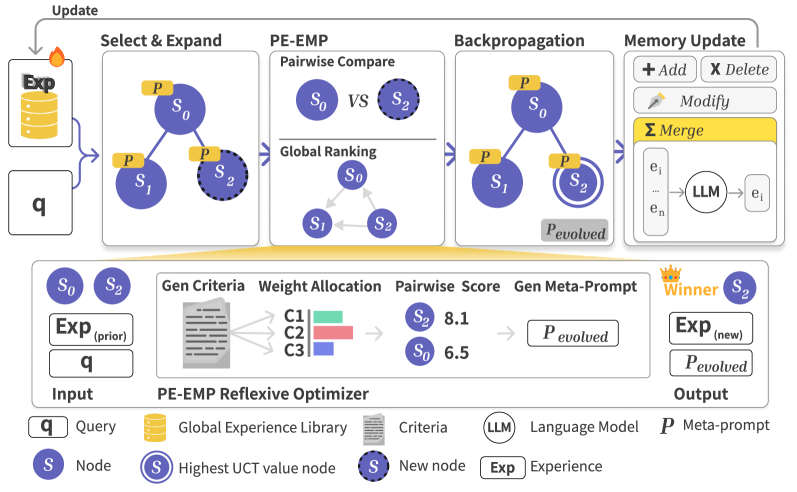
Empirical-MCTS leverages Monte Carlo Tree Search and pairwise comparisons to create a self-improving reasoning framework for large language models.
While Large Language Models excel at complex reasoning, they typically lack the ability to accumulate wisdom across problem-solving instances. This limitation motivates the development of ‘Empirical-MCTS: Continuous Agent Evolution via Dual-Experience Monte Carlo Tree Search’, a novel framework that transforms stateless Monte Carlo Tree Search into a continuous learning process. By unifying local exploration with global memory optimization-through mechanisms like pairwise experience evolution and a dynamic policy prior-Empirical-MCTS enables LLMs to improve reasoning capabilities over time without parameter updates. Does this coupling of structured search with empirical accumulation represent a crucial step toward truly open-ended, adaptive intelligence in artificial agents?
The Limits of Scalability: Beyond Pattern Matching in Language Models
Despite the impressive performance of Large Language Models (LLMs) on a variety of benchmarks, these systems frequently encounter difficulties when confronted with reasoning challenges that require multiple, interconnected steps. Tasks demanding the synthesis of information from disparate sources, or the application of logical rules over extended sequences, often expose the limitations of LLMs’ pattern-matching approach. While proficient at identifying correlations within training data, they struggle with true causal inference or the ability to generalize to novel situations not explicitly represented in their dataset. This suggests that simply increasing model size – a common strategy for improvement – eventually yields diminishing returns, highlighting the need for architectural innovations that go beyond scaling to address the fundamental problem of complex reasoning.
The pursuit of ever-larger language models, while initially successful, is now encountering the law of diminishing returns. Increasing the number of parameters and training data yields progressively smaller gains in reasoning ability, suggesting that simply making models bigger is not a sustainable path toward true intelligence. This limitation stems from the fundamental architecture of these models, which primarily excel at pattern recognition rather than genuine inferential thought. Consequently, researchers are actively exploring alternative approaches to knowledge processing, moving beyond brute-force scaling to focus on architectures that can more effectively represent, manipulate, and reason with information – seeking methods that prioritize efficient inference over sheer data capacity.
Traditional approaches to language processing often rely on sequential processing, where information is handled in a linear fashion – one word or phrase after another. However, this methodology frequently falls short when confronted with complex reasoning tasks because it struggles to adequately represent the intricate relationships between different pieces of information. Robust reasoning demands a capacity to integrate knowledge from multiple sources, identify dependencies, and consider alternative perspectives – a holistic understanding that purely sequential models often miss. The nuances of context, the weighting of evidence, and the ability to backtrack or revise assumptions are all diminished when information is treated solely as a linear stream, highlighting the need for architectures capable of capturing a more interconnected and dynamic representation of knowledge.
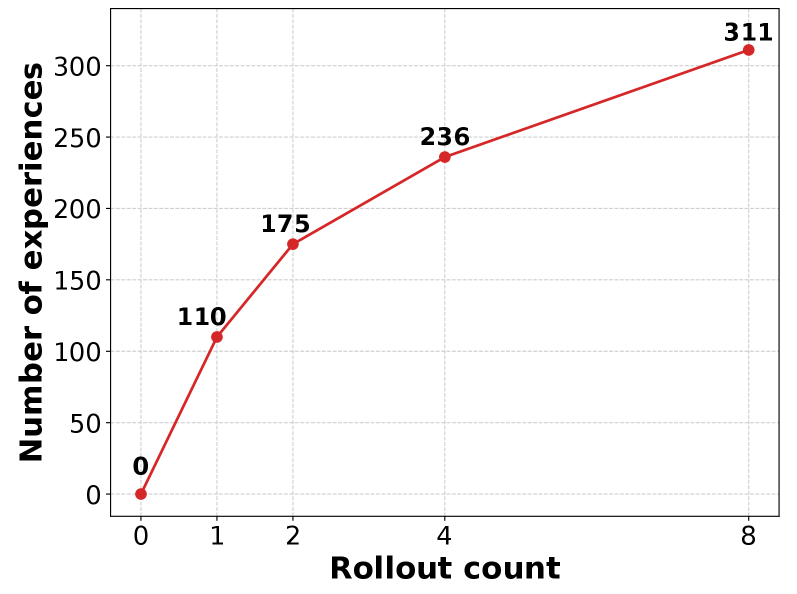
Empirical-MCTS: A Structured Framework for Reasoning
Empirical-MCTS is a novel framework designed to integrate the benefits of structured search methodologies with continuous learning techniques. It is built upon Monte Carlo Tree Search (MCTS), a search algorithm well-suited for decision-making in complex environments. Unlike traditional MCTS implementations, Empirical-MCTS extends the core algorithm to facilitate ongoing refinement through experience. This is achieved by actively learning from the search process itself, allowing the system to improve its reasoning capabilities over time. The framework’s architecture allows for the exploration of diverse reasoning pathways and the evaluation of potential outcomes, with the goal of achieving more robust and adaptable decision-making.
The core of Empirical-MCTS is a search tree constructed to facilitate the systematic exploration of possible reasoning trajectories. Each node in the tree represents a specific state within the problem space, and edges denote potential actions or inferences that transition between states. This tree-based structure allows the algorithm to move beyond single-path reasoning and consider multiple alternative paths concurrently. During tree traversal, each path is evaluated based on its predicted outcome, enabling the algorithm to assess the potential benefits and drawbacks of different reasoning strategies. The depth and breadth of the search tree are dynamically adjusted to balance computational cost with the need for thorough exploration of the solution space.
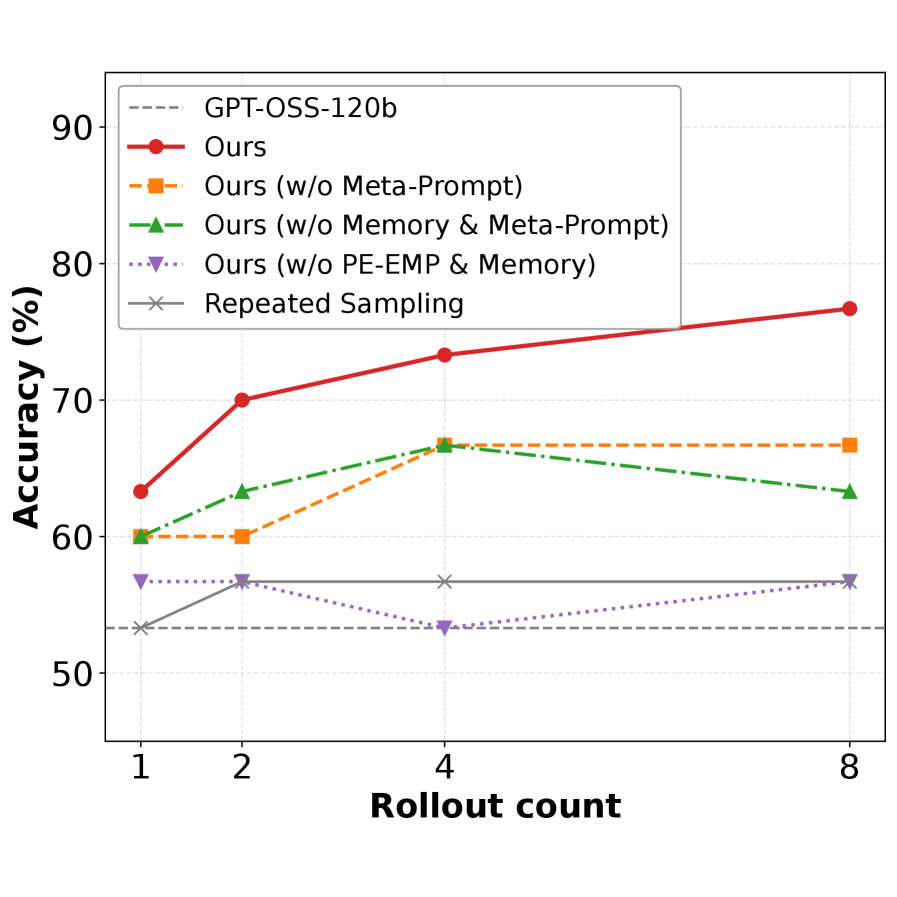
Empirical-MCTS incorporates a Memory Optimization Agent responsible for maintaining and updating a global Experience Library during the search process. This agent distills successful reasoning paths and outcomes into reusable knowledge stored within the library. The library functions as an evolving repository of learned information, enabling the system to avoid redundant exploration and accelerate future searches. Evaluations on the AIME25 dataset demonstrate the efficacy of this approach, yielding an accuracy of 73.3%.
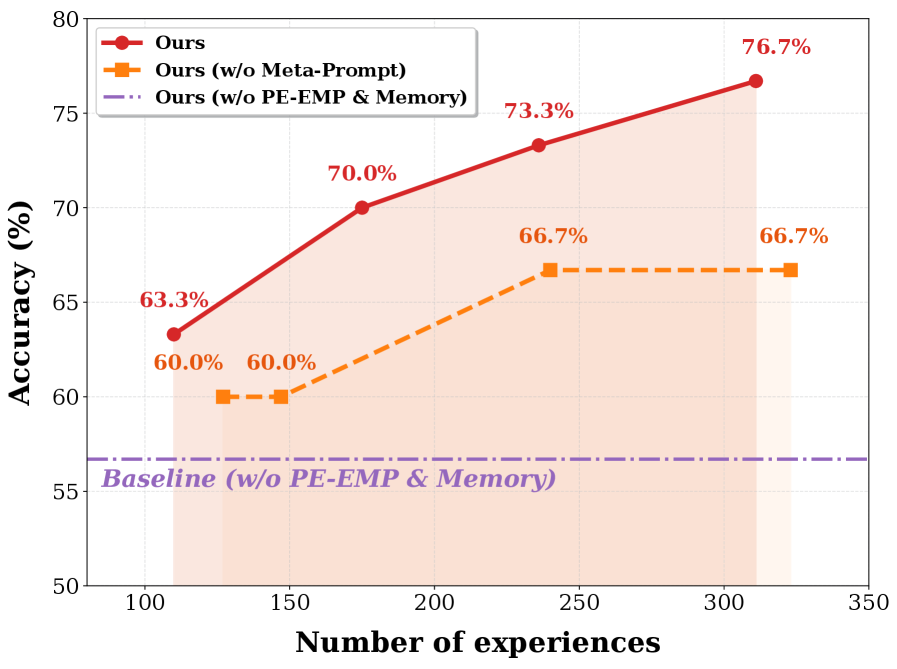
Refining Reasoning with Pairwise Feedback: A Meta-Prompting Approach
Pairwise-Experience-Evolutionary Meta-Prompting is a central element of Empirical-MCTS, functioning as an iterative refinement process for the Meta-Prompt used to guide reasoning. This process involves presenting the model with pairs of reasoning paths – generated responses to a given problem – and soliciting feedback to determine which path is superior. This comparative assessment allows the system to update the Meta-Prompt, steering the generation policy towards more effective reasoning strategies. The resulting Meta-Prompt is then used to generate new reasoning paths, continuing the cycle of pairwise comparison and refinement, ultimately improving the overall quality of generated solutions.
The refinement of reasoning paths within Empirical-MCTS utilizes both the Enhanced Borda Count and the Bradley-Terry Model for comparative assessment. The Enhanced Borda Count assigns points to different reasoning paths based on their rank in pairwise comparisons, providing a collective score reflecting relative preference. Complementing this, the Bradley-Terry Model statistically estimates the probability of one reasoning path being preferred over another, modeling the underlying strength of each path based on observed pairwise outcomes. This combination allows the system to not only rank paths but also quantify the degree of preference, leading to a more robust and accurate selection of optimal reasoning strategies.
Forward Learning integration demonstrably improves performance on the MathArena Apex benchmark, achieving 4.17% accuracy. This represents a significant gain compared to the 0.00% accuracy of the base model and the 2.08% accuracy attained by LLaMA-Berry. Cost analysis indicates that utilizing Gemini 3 Flash with Forward Learning reduces computational expenses to $3.40, a substantial decrease from the $12.00 cost associated with GPT-5.2 (High) for the same tasks.
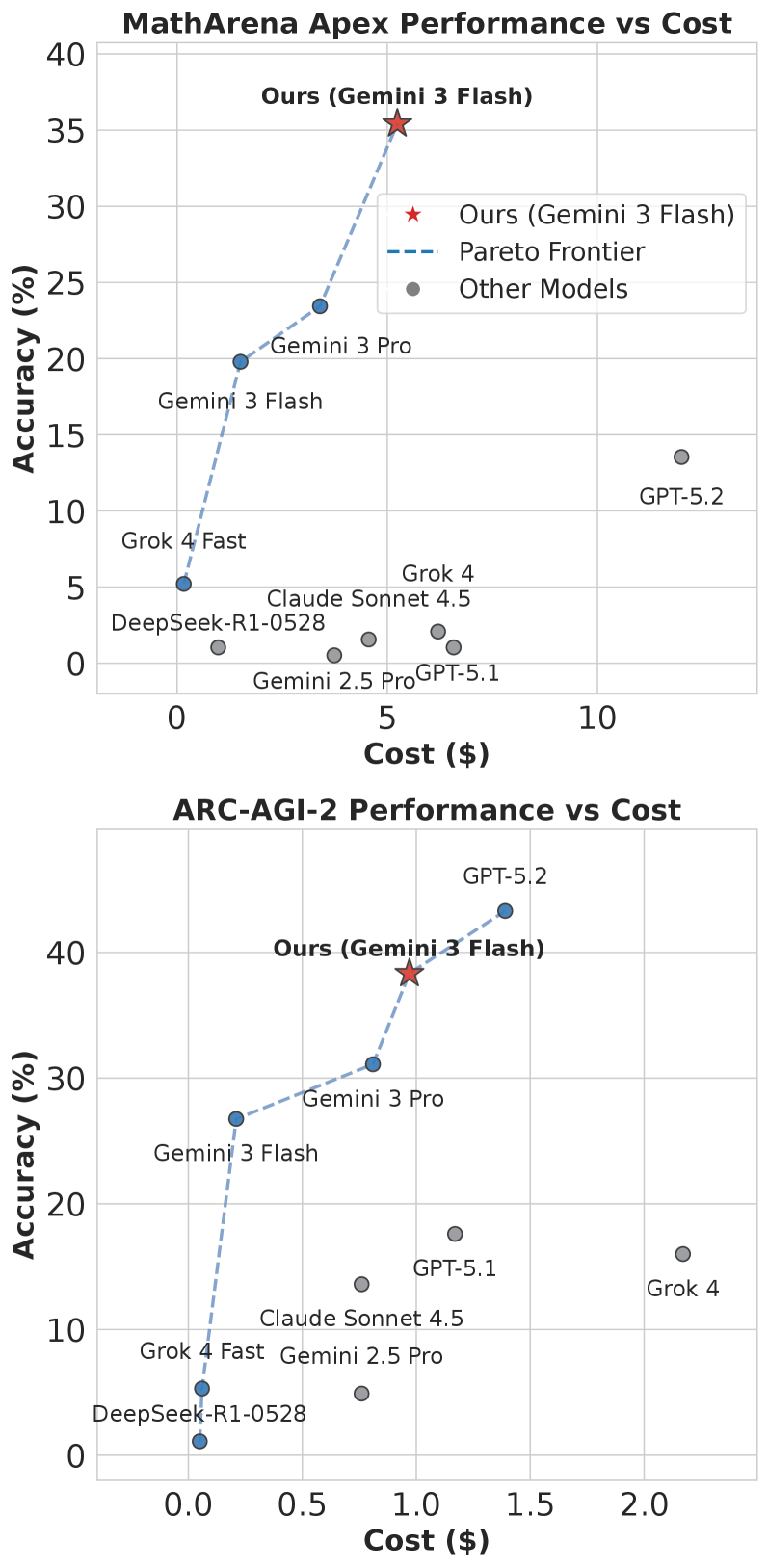
Performance Across Domains: Establishing a New Standard in Reasoning
The integration of Empirical-MCTS with leading large language models-including DeepSeek-V3.1-Terminus, gpt-oss-120b, and Gemini 3 Pro-establishes a new standard in performance across challenging benchmarks. This synergistic approach consistently achieves state-of-the-art results on diverse problem sets like AIME25, known for its demanding mathematical problems, the ARC-AGI-2 challenge emphasizing abstract reasoning, and the competitive MathArena Apex. By combining the exploratory power of MCTS with the knowledge and generative capabilities of these powerful LLMs, the system demonstrates an ability to not only process information but also to strategically navigate complex problem spaces, consistently surpassing previous performance levels and setting a benchmark for future AI development.
Empirical-MCTS demonstrates a significant advantage in domains demanding intricate logical deduction, notably excelling in complex mathematical reasoning and geometric proofs. Recent evaluations reveal an accuracy of 38.33% on the challenging ARC-AGI-2 benchmark, surpassing the performance of established models like Gemini 3 Pro, which achieved 31.1%, and Grok 4, which registered only 16.0%. This proficiency extends to MathArena Apex, where the framework attains 35.42% accuracy when paired with Gemini 3 Flash, highlighting its capacity to navigate and solve problems requiring multi-step, abstract thought processes. These results suggest that a structured reasoning approach, such as Empirical-MCTS, can substantially elevate performance in areas where simply increasing model scale proves insufficient.
The recent performance of Empirical-MCTS, when paired with large language models, suggests a shift in the landscape of artificial intelligence problem-solving. While simply increasing the size of these models – a ‘scaling-based’ approach – has yielded considerable progress, certain complex tasks continue to pose significant challenges. This work demonstrates that incorporating a structured reasoning framework, like Empirical-MCTS, allows for more effective navigation of intricate problem spaces. By systematically exploring possibilities and evaluating outcomes, the framework complements the knowledge and predictive capabilities of the language model, resulting in substantial gains in areas like mathematical reasoning and geometric proofs. This indicates that future advancements in AI may depend not only on model scale, but also on the development of architectures that prioritize and facilitate deliberate, structured thought processes.
Towards General AI Reasoning: Future Directions and Research
Ongoing research endeavors are centered on augmenting Empirical Monte Carlo Tree Search (MCTS) with more nuanced methods of knowledge representation and learning. Current iterations primarily rely on relatively simple state-action spaces; future developments will explore incorporating knowledge graphs and semantic embeddings to provide the system with a richer understanding of the problem domain. This enhanced understanding will allow Empirical-MCTS to not only evaluate potential actions more effectively, but also to generalize learned strategies to novel situations. Furthermore, integrating machine learning techniques-such as reinforcement learning and meta-learning-into the search process promises to enable the system to adapt its reasoning approach dynamically, improving performance and efficiency across diverse and complex challenges.
Current research suggests a promising pathway to bolster AI reasoning through the synergistic combination of Training-Free Goal-Conditioned Reinforcement Learning with Policy Optimization (GRPO) and the Self-Refine methodology. GRPO offers the potential to establish robust reasoning strategies without the need for extensive, labeled training datasets, allowing the system to adapt more readily to novel situations. By integrating this with Self-Refine – a process enabling the AI to critically evaluate and iteratively improve its own reasoning steps – the framework gains a powerful capacity for self-optimization. This combined approach moves beyond simply executing a reasoning process; it allows the system to actively refine that process, identifying and correcting errors in its own logic, and ultimately leading to more accurate and adaptable problem-solving capabilities.
The long-term objective of this line of inquiry extends beyond incremental improvements in specific AI tasks; it envisions a fundamental shift towards reasoning systems possessing genuine generality and adaptability. Current AI often excels within narrowly defined parameters, struggling when confronted with novel situations or problems requiring flexible problem-solving. This research strives to overcome these limitations by developing systems capable of not just performing tasks, but understanding the underlying principles, allowing them to transfer knowledge and reasoning skills across diverse domains. The ultimate goal is to create AI that can approach complex, real-world challenges with the same fluidity and ingenuity as human cognition, thereby unlocking potential applications in fields ranging from scientific discovery to autonomous decision-making and beyond.
The presented work emphasizes a systemic approach to enhancing Large Language Model reasoning, mirroring the interconnectedness of complex systems. Empirical-MCTS achieves improvement not through direct parameter modification, but through the accumulation of experience and refinement of meta-prompting strategies – a process akin to understanding the whole bloodstream rather than simply replacing the heart. This resonates with Ada Lovelace’s observation that, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” The framework doesn’t invent new reasoning pathways, but meticulously learns and optimizes existing ones, demonstrating that structure – in this case, the search tree and experience replay – fundamentally dictates behavior and emergent capabilities.
What Lies Ahead?
The elegance of Empirical-MCTS resides in its circumvention of parametric updates – a move that, while appealing, merely shifts the locus of complexity. The system’s performance is inextricably linked to the quality of the experience replay buffer, and therefore to the initial meta-prompt and the framing of pairwise comparisons. This framework, like any situated intelligence, will ultimately betray the biases embedded within its initial conditions. The boundaries of its knowledge are not walls, but rather gradients- imperceptible until a novel situation exposes the system’s inability to extrapolate beyond its accumulated experience.
Future work must address the question of ‘forgetting’ – not in the algorithmic sense of buffer overflow, but in the deeper sense of discerning which experiences truly contribute to generalized reasoning ability. A system that indiscriminately hoards every interaction risks ossification, becoming a brittle archive of past successes rather than a flexible intellect. The true challenge lies in building mechanisms for experience distillation, for identifying and retaining only the essential structures that underpin robust inference.
Ultimately, the pursuit of continual learning in large language models will reveal not the path to artificial general intelligence, but rather the limitations inherent in any system predicated on pattern recognition. Structure dictates behavior, and these models, however sophisticated, remain fundamentally bound by the structures within their training data and the biases of their creators. The cracks will appear along these invisible boundaries – and it is in anticipating these failures, not celebrating successes, that genuine progress will be found.
Original article: https://arxiv.org/pdf/2602.04248.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- What Song Is In The New Supergirl Trailer (& What It Means For The DC Movie)
- Highly Anticipated Strategy RPG Finally Sets Release Date (And It’s Soon)
- TV legend Carol Kirkwood reveals the reasons why she decided to retire after 28 years with BBC
- Dune 3 Gets the Huge Update Fans Have Been Waiting For
- Why is Tech Jacket gender-swapped in Invincible season 4 and who voices her?
- Palworld! More Than Just Pals ‘Special Video’, characters detailed
- How Blake Lively & Ryan Reynolds’ Kids Pranked Her on April Fool’s Day
- The OG Resident Evil 1, 2 and 3 Are Now Available on Steam With a Heavy Discount (and DRM)
- The Monsterverse’s Shocking New Time Travel Story – Monarch: Legacy Of Monsters Season 2, Episode 6 Explained
- Tainted Grail: The Fall of Avalon – Merlin’s Tomb DLC Adds a New End-Game Dungeon for Free
2026-02-05 18:09