
AI technology is not going anywhere, and it extends beyond merely utilizing web-based tools such as ChatGPT and Copilot. If you’re a developer, an enthusiast, or simply eager to acquire fresh knowledge and gain insights into how these technologies operate, local AI solutions are worth considering over their remote counterparts.
Using Ollama for experimenting with LLMs on your personal computer is straightforward and widely preferred. However, unlike using ChatGPT, a robust local system with powerful hardware is essential due to its current support for dedicated GPUs only. If you’re using LM Studio with integrated GPUs, you’ll still require a decent machine for optimal performance.
You might think that investing a substantial sum is necessary for a high-end graphics card like the RTX 5090. However, it’s not essential. Although splurging on a top-tier card is an option, you can also consider purchasing older or more affordable models that still offer good performance. If your budget allows for an NVIDIA H100, go ahead, but there are also less expensive alternatives worth considering.
VRAM is key for Ollama
As a tech enthusiast, I’d say that when it comes to purchasing a GPU (Graphics Processing Unit) for AI (Artificial Intelligence), the focus isn’t the same as for gaming. While shopping for a gaming rig, you often aim for the newest generation and the most powerful card your budget allows, chasing after the best visuals and highest frame rates. However, when it comes to AI, you might want to consider factors like double precision support, tensor cores, memory bandwidth, and other features optimized for machine learning tasks rather than graphics performance.
In terms of AI purchases, there’s a certain aspect where quantity matters, but it’s not as crucial for home users. For instance, the new 50 series GPUs might boast more CUDA cores, faster processing speeds, and superior memory bandwidth. However, when it comes to truly ruling the roost, memory takes the crown.
If your budget isn’t expansive enough for the top-of-the-line AI graphics cards currently available, focus on acquiring as much Video Random Access Memory (VRAM) as possible. A larger amount of VRAM will help optimize your system’s performance when dealing with complex graphics processing tasks.
Whenever your CPU needs to take on additional tasks, as it does in Ollama when this occurs, you’ll experience a significant drop in performance.
To maximize your GPU’s potential with local Large Language Models (LLMs), ensure that the model runs entirely within the GPU’s Video Random Access Memory (VRAM). Since VRAM is quicker than standard system memory, keeping everything in VRAM minimizes performance loss. However, when data starts overflowing into system RAM, you’ll experience a drop in performance as the CPU steps in to help, which can significantly slow down the process, such as in Ollama when this occurs.
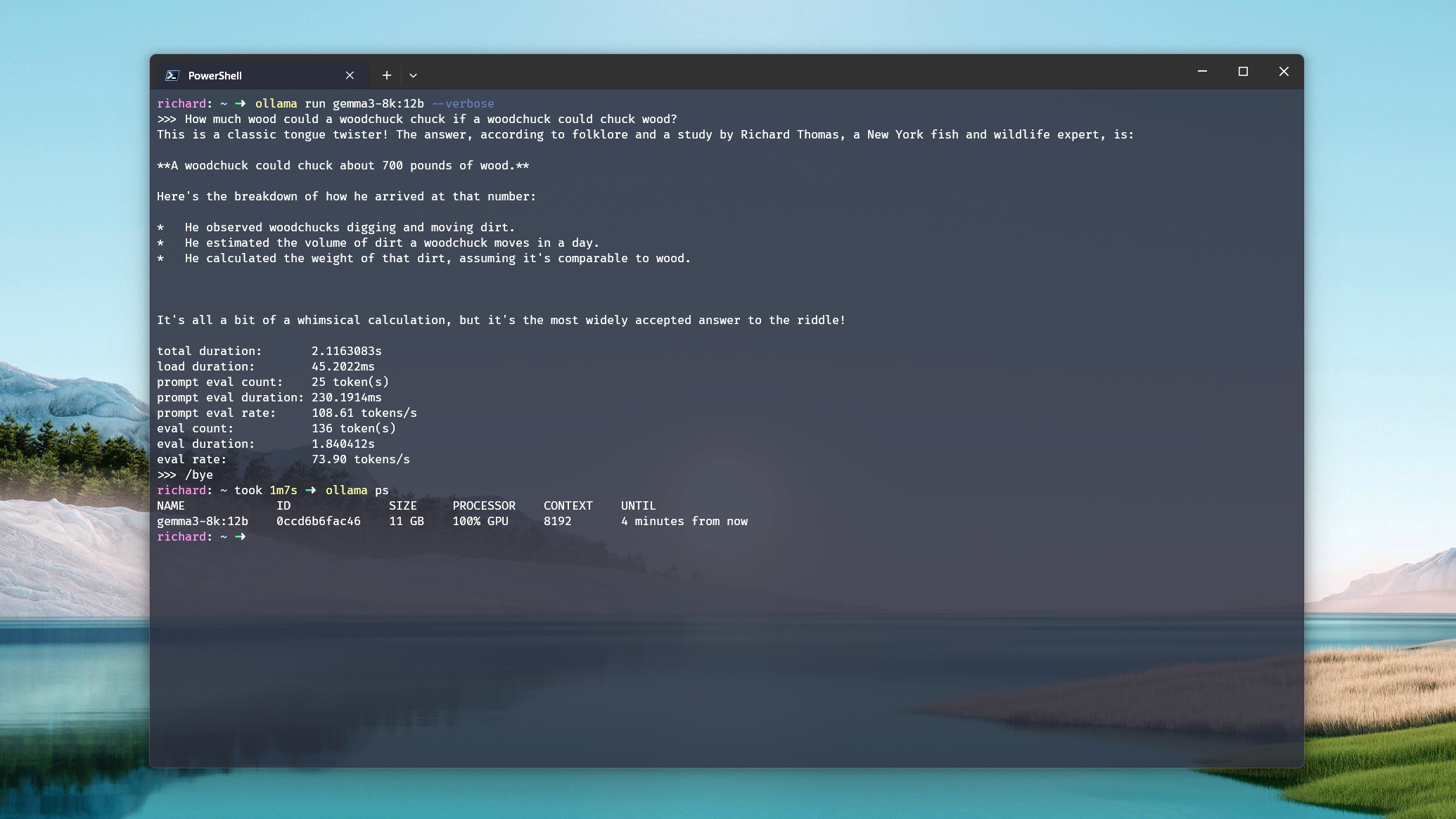
On my personal computer, Deepseek-r1:14b, equipped with an NVIDIA RTX 5080 graphics card having 16GB VRAM, a powerful Intel Core i7-14700k processor, and 32GB DDR5 RAM, is operational. When I provide it with a simple command like “tell me a story,” the model generates approximately 70 tokens per second. However, if I expand the context window beyond 16k, the model begins to utilize both the system RAM and CPU since it exceeds the GPU memory capacity.
In my analysis, I’ve noticed a significant decrease in output speed to approximately 19 tokens per second, despite the CPU and GPU being split at 21%/79%. Interestingly, even when the GPU is performing the majority of the tasks, a call for the CPU and RAM seems to lead to a dramatic drop in performance.
In similar vein, laptops are no exception, although our discussion here primarily revolves around desktop graphics cards. When artificial intelligence holds significance, it’s best to opt for a laptop equipped with a GPU featuring the maximum amount of Video Random Access Memory (VRAM) available.
So, how much VRAM do you need?

As extensively as your resources permit. However, the precise answer depends on the specific models you plan to utilize. While I can assist you in determining your needs, I won’t be able to provide an exact solution for you.
On Ollama’s website’s models page, each model is displayed with its size specified. This minimum size indicates the amount of VRAM required to load the entire memory onto your GPU. However, for effective processing, you’ll require more than this. The larger the context window, which feeds data into the Language Learning Model (LLM), the more memory you’ll consume, also referred to as the KV cache. In simpler terms, a larger context window means more data will be stored in memory for the model to process effectively.
In an optimal scenario, I’d recommend having a graphics card with 24GB of VRAM if you plan to utilize this model freely and smoothly.
A common suggestion is to multiply the actual file size of a model by 1.2 as an approximate estimate of its final size. Let me illustrate with an example!
14 gigabytes is the size of OpenAI’s gpt-oss:20b model. If you multiply that by 1.2, it yields a figure of approximately 16.8GB. Based on my own usage, this estimation seems fairly accurate. Without utilizing a 16GB RTX 5080 GPU with an 8k or smaller context window, I’m unable to maintain the entire model loaded on the graphics card.
In a perfect scenario, when dealing with CPUs and RAM at 16k and beyond, performance significantly drops off like a steep cliff. Therefore, for optimal use, I recommend a GPU with 24GB of VRAM to handle this model effectively.
This statement can be rephrased as follows:
The point made earlier is echoed here: The more tasks you assign to the CPU and RAM, the poorer your system’s performance becomes. To maintain optimal performance, aim to keep the GPU active for as long as possible, regardless if it’s due to larger models, bigger context windows, or a blend of both.
Older, cheaper GPUs can still be great buys for AI

After spending sufficient time exploring online, it becomes evident that a recurring trend appears. Numerous individuals believe that, at present, the RTX 3090 offers the optimal balance for power users – a combination of cost-effectiveness, video memory (VRAM), and computational performance.
In simpler terms, when considering only the number of CUDA cores and memory bandwidth, the RTX 3090 performs similarly to the RTX 5080. However, the RTX 3090 has a significant advantage in VRAM, with 24GB compared to the RTX 5080’s none. The TDP (power consumption) of the RTX 3090 is also lower than that of the more expensive and power-hungry RTX 4090 and RTX 5090.
On the other hand, the RTX 3060 has become quite popular in AI communities due to its 12GB VRAM and lower cost. Although it has less memory bandwidth and a smaller TDP of 170W, you could use two RTX 3060 GPUs to match the total VRAM and power consumption of an RTX 3090, while spending considerably less money.
With sufficient time spent browsing online, it becomes apparent that there’s a recurring trend. Numerous individuals contend that the RTX 3090 currently offers the most value for power users.
Instead, consider investing wisely rather than rushing to purchase the costliest, top-of-the-line graphics card available. It’s all about finding the right balance based on your specific needs, so take some time to explore and understand what you require.
First, determine your desired budget for the GPU purchase. Aim to get the fastest GPU with the maximum VRAM capacity it can offer. As Ollama allows multi-GPU usage, consider buying two 12GB GPUs if they are less expensive than a single 24GB card, as this could be a cost-effective solution.
And finally…

If possible, consider opting for NVIDIA GPUs at this moment, especially for local AI applications. While Ollama does support some AMD GPUs, NVIDIA currently offers more suitable options due to their significant lead in advancements related to AI technology. AMD is catching up, but NVIDIA’s head start makes them a preferable choice at the current time.
Despite some challenges, AMD excels notably in its mobile processors designed for laptops and compact PCs. For roughly the same cost as a top-tier graphics card today, you could acquire an entire mini PC equipped with the Strix Halo generation Ryzen AI Max+ 395 APU coupled with 128GB of unified memory. Furthermore, it comes with desktop-class Radeon 8060S integrated graphics, a true testament to its capabilities.
Ollama won’t work on a system using Ryzen AI chips as they don’t support iGPUs. However, LM Studio, which has Vulkan support, is compatible. A 128GB Strix Halo system provides up to 96GB of memory for large language models (LLMs), which is quite substantial.
You’ve got some choices available, and they include more cost-effective options. If the GPU you prefer is part of an older generation, examine Ollama’s list for possible alternatives. Aim to acquire as much Video Random Access Memory (VRAM) as feasible, even if it means using multiple GPUs when appropriate. If you manage to find a pair of 12GB RTX 3060s priced between $500 and $600, you’re on your way to an excellent setup.
Don’t let your equipment or financial constraints hold you back from participating. Instead, spend a bit of time researching to ensure you get the best value for your investment and enjoy the experience fully.
Read More
- Gold Rate Forecast
- Hazbin Hotel Secretly Suggests Vox Helped Create One of the Most Infamous Cults in History
- Every Creepy Clown in American Horror Story Ranked
- 4 TV Shows To Watch While You Wait for Wednesday Season 3
- 40 Inspiring Optimus Prime Quotes
- 10 Best Buffy the Vampire Slayer Characters Ranked
- Arknights: Endfield – Everything You Need to Know Before You Jump In
- Best X-Men Movies (September 2025)
- PlayStation Plus Game Catalog and Classics Catalog lineup for July 2025 announced
- Chill with You: Lo-Fi Story launches November 17
2025-08-25 22:41