If you plan to utilize Ollama for running local Large Language Models on your computer, particularly Windows systems, you’ve got two feasible methods. Option one involves simply using the Windows application directly. Alternatively, you can opt for running the Linux version within Windows Subsystem for Linux (WSL).
The initial setup is undeniably more straightforward. For starters, there’s no requirement for Windows Subsystem for Linux (WSL) to be installed prior. Furthermore, the procedure to get it operational is less complex. All you need to do is download the Windows installer, execute it, and you’re good to go!
Installing Ollama on WSL involves some extra steps, but it works well with Ubuntu and delivers exceptional performance (especially when an NVIDIA GPU is involved). However, unless you’re a developer who prefers WSL for your workflows, there isn’t typically much advantage in using the WSL version over the standard Windows one.
Getting Ollama set up on WSL

In this write-up, I’ll provide some general pointers on how to set up Ollama on WSL, but it won’t cover all the aspects. If you’re aiming to use Ollama in a Windows Subsystem for Linux (WSL) environment, particularly with Ubuntu as it appears to be the easiest and best-documented option, there are some preliminary steps to follow. This guide is specifically tailored for NVIDIA GPUs.
In simpler terms, I’ll give you a basic roadmap for setting up Ollama on WSL using Ubuntu, but it won’t cover every detail. The focus here is for NVIDIA GPUs and the setup process with WSL.
1. The first one is a recently updated NVIDIA graphics driver compatible with Windows.
2. The second one is a CUDA toolkit customized for WSL (Windows Subsystem for Linux). If you have both of these, it’s like magic will occur automatically. A good starting point would be to consult the documentation provided by Microsoft and NVIDIA for a step-by-step guide on the process.
The process isn’t particularly lengthy, but it does depend on the quality of your internet connection for you to successfully download all necessary files.
Although it won’t take much time, the speed at which you get the required files depends on the strength of your internet connection.
After taking care of everything, feel free to execute the installation script which will help you set up Ollama on your system. Keep in mind that I haven’t delved into running Ollama inside a container on WSL; my familiarity with it is limited to installing it directly onto Ubuntu.
During the setup procedure, the system will autonomously identify an NVIDIA graphics card provided that all necessary configurations are in place. You’ll notice a message appearing, indicating “NVIDIA Graphics Card Installed,” while the script continues to execute.
Moving forward, the experience is similar to running Ollama on Windows, except there isn’t a graphical user interface (GUI) application involved. You can start by downloading your initial model, and you’re all set. However, it’s worth noting that if you switch back to Windows, there might be a minor difference in operation.
When you’re using WSL (Windows Subsystem for Linux) in a separate window, Ollama within Windows will only acknowledge the models you’ve installed on WSL as being active. If you check the `ollama list` command, you won’t find any models that you’ve installed on your regular Windows system. Trying to run a model you know you have installed may prompt it to download again.
To make sure Ollama works correctly on Windows, it’s essential to properly close the WSL environment first. This can be done by typing the command “wsl shutdown” in a PowerShell window.
Almost identical performance in WSL to using Ollama on Windows
Let me bring up some figures soon, but first, let me emphasize a minor yet important detail: Running Windows Subsystem for Linux (WSL) consumes some of your total system resources. Although it may not significantly impact the big picture, it’s crucial to be aware of this resource usage.
Within the WSL settings application, you can effortlessly adjust the RAM and CPU thread allocation for WSL according to your preference. If you mainly focus on GPU-intensive tasks, these settings might not be as crucial. However, if you plan to work with models that exceed your VRAM capacity, it’s essential to allocate adequate resources to WSL to compensate.
Keep in mind that if the model exceeds the VRAM limit, Olama might utilize the standard computer memory along with the CPU. So, make sure you assign memory appropriately.
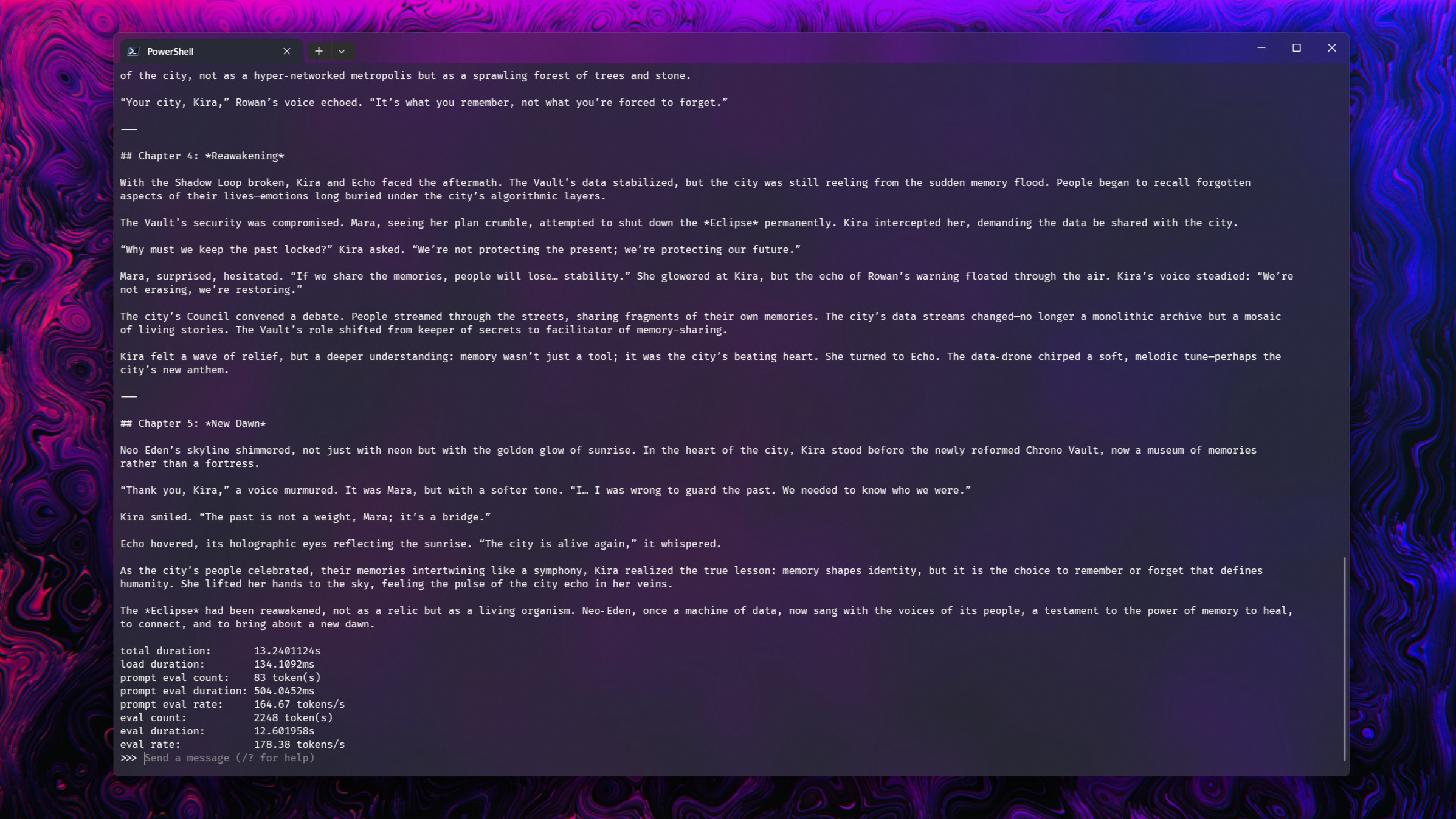
It’s important to note that these tests are quite basic, as I’m not focusing on the accuracy of the results but rather demonstrating similar performance levels among them. Four models – deepseek-r1:14b, gpt-oss:20b, magistral:24b, and gemma3:27b – have been examined because they all function smoothly on an RTX 5090 graphics card.
In each case, I asked the models two questions.
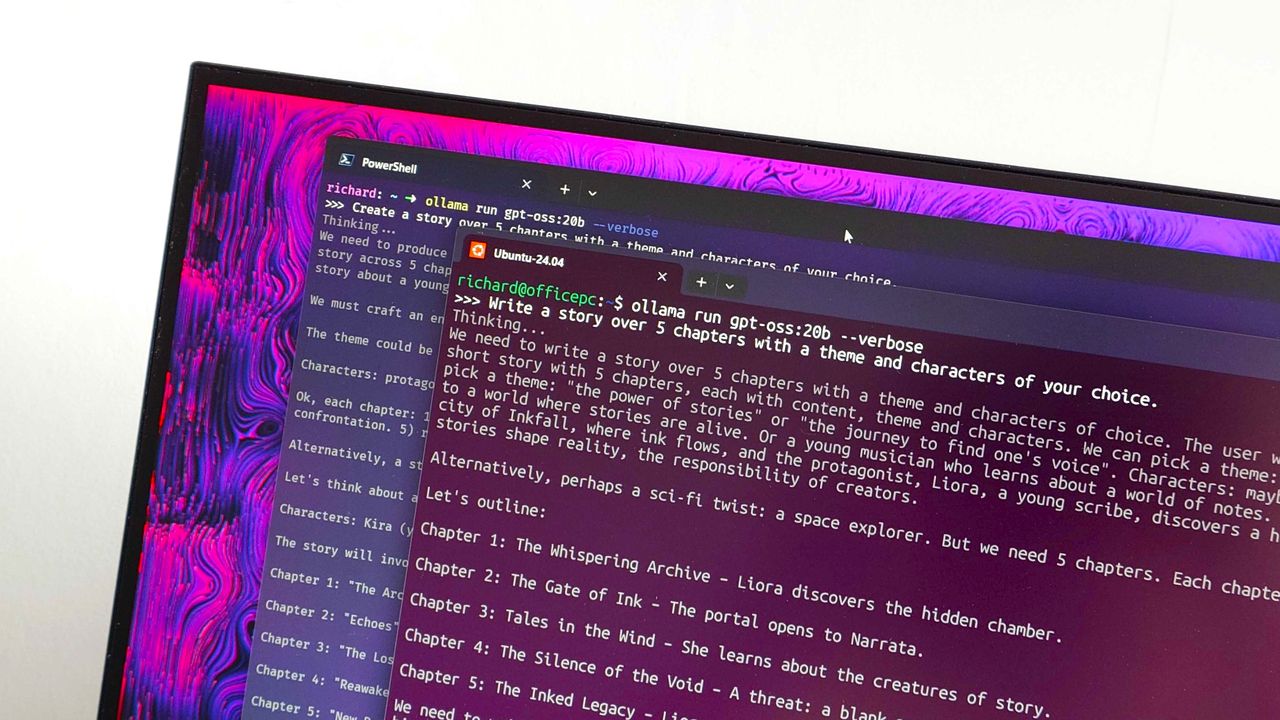
- Write a story over 5 chapters with a theme and characters of your choice. (Story)
- I want you to create a clone of Pong entirely within Python. Use no external assets, and any graphical elements must be created within the code. Ensure any dependencies are imported that are required. (Code)
And the results:
| WSL | Windows 11 | |
| gpt-oss:20b | Story: 176 tokens/secCode: 177 tokens/sec | Story: 176 tokens/secCode: 181 tokens/sec |
| magistral:24b | Story: 78 tokens/secCode: 77 tokens/sec | Story: 79 tokens/secCode: 73 tokens/sec |
| deepseek-r1:14b | Story: 98 tokens/secCode: 98 tokens/sec | Story: 101 tokens/secCode: 102 tokens/sec |
| gemma3:27b | Story: 58 tokens/secCode: 57 tokens/sec | Story: 58 tokens/secCode: 58 tokens/sec |
There are some minor fluctuations, but performance is as near as makes no difference, identical.
In simple terms, when Windows Subsystem for Linux (WSL) is running, it consumes extra RAM compared to when it’s not. However, as none of the models used more VRAM than they were allocated, this didn’t affect their performance in any way.
For developers working in WSL, Ollama is just as powerful
A typical individual like me (and who enjoys working with WSL) generally wouldn’t find it necessary to delve into utilizing Ollama in the manner you described. For now, my primary interaction with Ollama is for educational purposes, serving both as a learning tool and a means to deepen my understanding of its inner workings.
You can certainly use it on Windows 11, whether directly in the terminal or integrated with the Page Assist browser extension, which I’ve been experimenting with lately.
WSL serves as a connection point for developers between Windows and Linux. By employing Ollama, developers who rely on WSL can do so without sacrificing performance.
This version aims to maintain the original meaning while using simpler language and sentence structure.
Today, it’s still somewhat astonishing how seamlessly Linux can operate within Windows, allowing for complete utilization of an NVIDIA GPU. Remarkably, it functions just as smoothly.
Read More
- Gold Rate Forecast
- Looks Like SEGA Is Reheating PS5, PS4 Fan Favourite Sonic Frontiers in Definitive Edition
- Dune 3 Gets the Huge Update Fans Have Been Waiting For
- Pluribus Star Rhea Seehorn Weighs In On That First Kiss
- Arknights: Endfield – Everything You Need to Know Before You Jump In
- Jack Osbourne Shares Heartbreaking Tribute to Late Dad Ozzy Osbourne
- Every Upcoming Transformers Movie: Release Dates, Details, & Everything We Know
- Dungeon Stalkers to end service on June 9
- Antiferromagnetic Oscillators: Unlocking Stable Spin Dynamics
- Disney Promotes Thomas Mazloum To Lead Parks and Experiences Division As Josh D’Amaro Prepares To Become CEO
2025-09-03 18:19