Author: Denis Avetisyan
A new analysis reveals a dramatic shift in how physics students find information, with generative AI tools rapidly replacing traditional search engines.
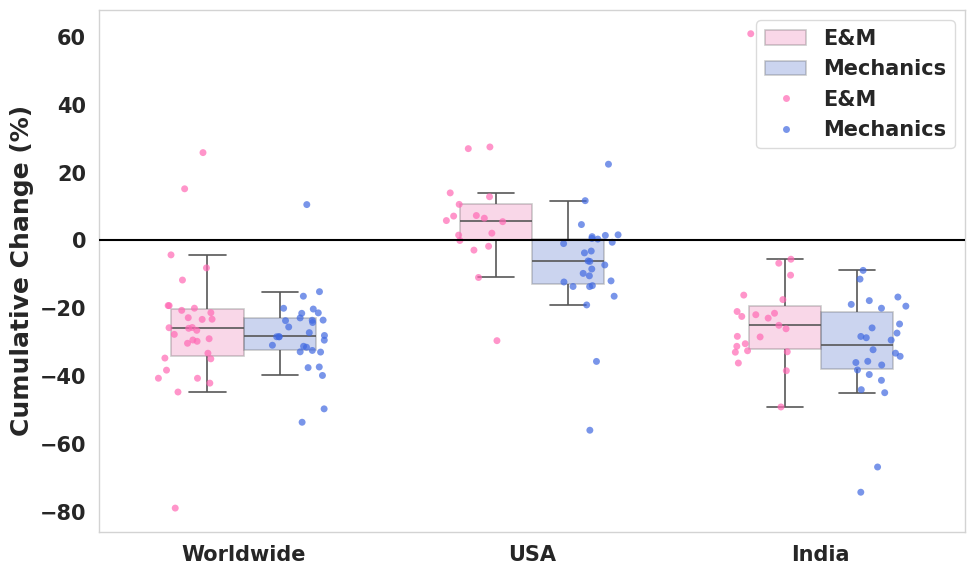
This study quantifies the global decline in search volume for physics topics and correlates it with the adoption of generative AI, highlighting potential impacts on learning patterns across different regions.
The increasing availability of generative AI tools presents a challenge to understanding how students access and engage with academic information. This is explored in ‘From Search to GenAI Queries: Global Trends in Physics Information-Seeking Across Topics and Regions’, a study analyzing shifts in online information-seeking behavior related to physics. The results reveal a substantial and consistent global decline in traditional search and page-view activity across core physics topics, particularly pronounced in non-English-speaking regions. Does this trend signal a fundamental redistribution of learning practices, and what implications does it hold for the future of physics education and digital literacy?
The Erosion of Direct Inquiry: A Systemic Shift
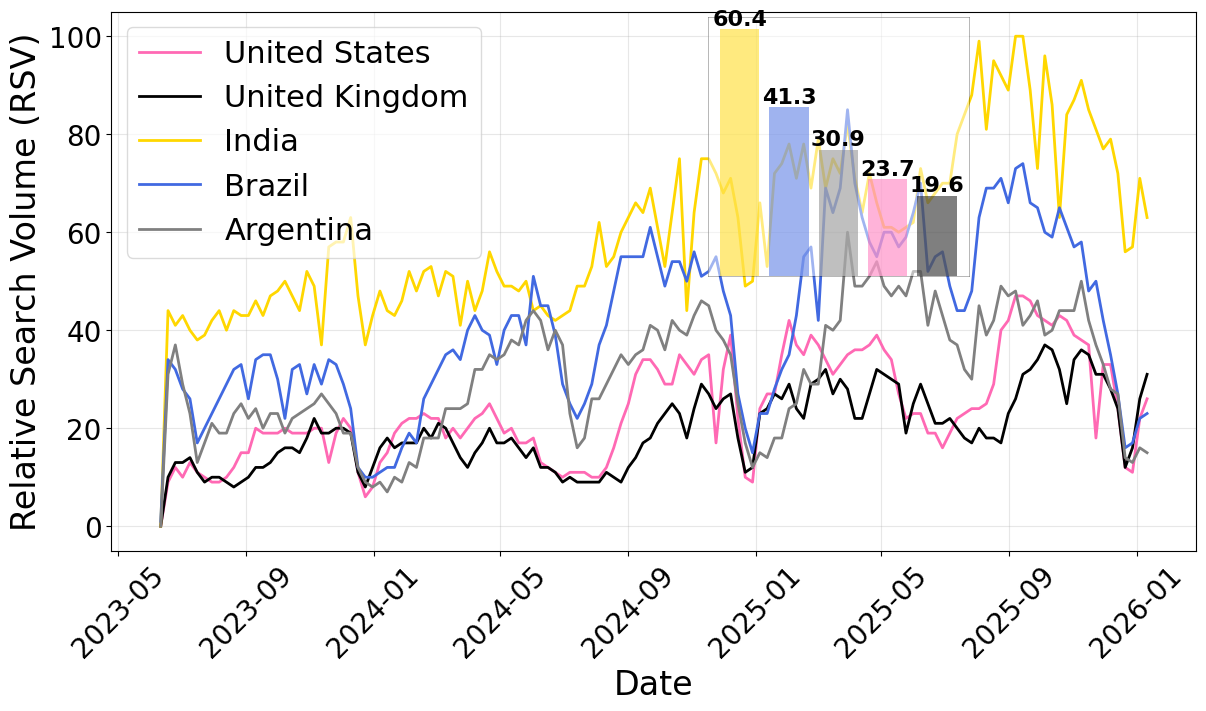
A significant shift in how individuals access information is becoming apparent through recent analyses of Google Trends data, which demonstrate a marked reduction in searches related to physics topics. The volume of these queries has declined considerably – exceeding a 50% drop in certain geographic regions – suggesting traditional methods of seeking knowledge may be undergoing a fundamental change. This isn’t simply a localized phenomenon; the trend is observed globally, indicating a broader societal pattern rather than a temporary fluctuation. While numerous factors could contribute to this decline, the data highlights a clear signal that warrants further investigation into evolving information-seeking behaviors and the potential displacement of conventional search methodologies.
Analysis of recent search data reveals a nuanced shift in public engagement with physics topics, as not all areas are experiencing decline equally. While overall physics-related searches are decreasing, foundational concepts within Mechanics demonstrate a considerably steeper drop – nearly 39.83% globally – compared to the 25.67% decrease observed in Electromagnetism. This disparity suggests a potentially uneven impact of evolving information access methods, prompting investigation into why core mechanical principles might be receiving comparatively less direct inquiry. Researchers hypothesize this could relate to the greater availability of pre-digested explanations of electromagnetism in popular science media, or perhaps a changing emphasis in STEM curricula, leaving Mechanics comparatively underrepresented in readily accessible content and therefore decreasing the need for independent search.
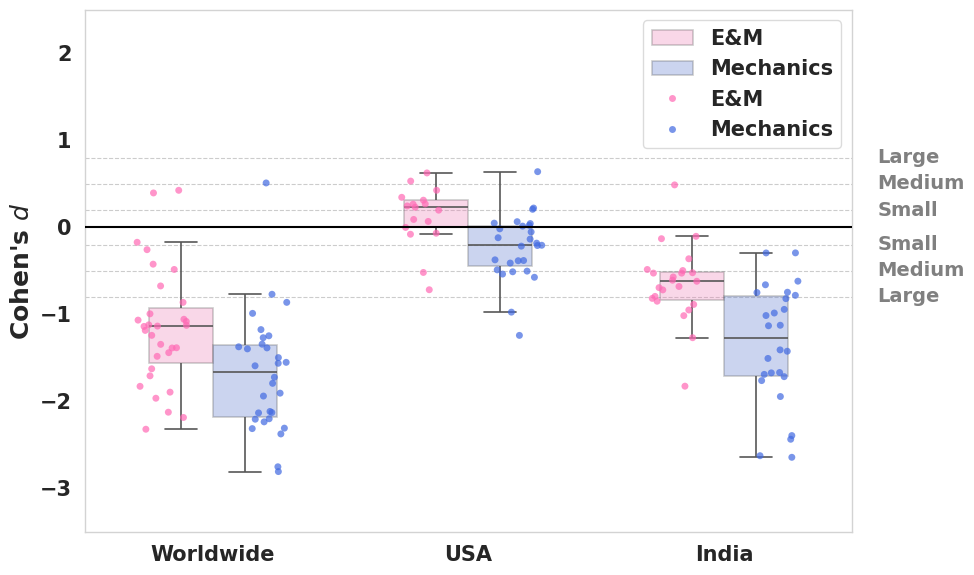
Contemporary shifts in how individuals access information appear increasingly linked to the rise of Generative AI (GenAI) tools. Recent data suggests a correlation between the growing prevalence of these technologies and a measurable decline in direct searches for physics concepts; notably, searches related to foundational Mechanics have experienced a particularly significant decrease. Statistical analysis reveals a large effect size – Cohen’s d = -2.37 globally – indicating that the observed reduction in Mechanics searches is unlikely due to random chance and may, in fact, reflect a substantive change in information-seeking behavior. This suggests that individuals are potentially turning to GenAI platforms for synthesized answers rather than independently researching specific topics, prompting further investigation into the evolving relationship between AI and scientific literacy.
The Evolving Skillset: From Queries to Instructions
Generative AI (GenAI) tools are increasingly capable of performing tasks beyond traditional information retrieval. Previously, users formulated search queries to receive a list of relevant documents, requiring manual analysis to locate answers. Current GenAI models, however, can directly process natural language questions and synthesize information from multiple sources to provide concise, directly applicable answers. This functionality extends to summarizing lengthy texts, translating languages, and generating novel content, effectively reducing the need for iterative search queries and manual data aggregation. The shift signifies a move from finding information to generating knowledge, impacting how users interact with and utilize digital resources.
Prompt Engineering is increasingly vital as Generative AI models move beyond simple keyword-based retrieval. Traditional information seeking relied on formulating precise search terms to match indexed content; however, GenAI models respond to natural language instructions – prompts – requiring users to articulate desired outputs. Effective prompts specify not only the information requested but also the desired format, style, and constraints, influencing the model’s response quality. This necessitates a skillset focused on clarity, conciseness, and iterative refinement of prompts to achieve predictable and accurate results, shifting the emphasis from keyword optimization to instruction design. The ability to engineer effective prompts directly impacts the utility and reliability of GenAI-driven insights.
Increased dependence on Generative AI necessitates robust critical thinking skills to verify the accuracy and reliability of generated content. While GenAI tools can efficiently synthesize information, they are prone to inaccuracies, biases, and the propagation of misinformation. Users must therefore actively evaluate sources, cross-reference information, and assess the logical consistency of AI outputs. This includes scrutinizing the provenance of data used to train the models and understanding the potential for algorithmic bias. The ability to distinguish between factual statements and AI-generated fabrications is becoming increasingly important, as reliance on unverified AI outputs can lead to flawed decision-making and the spread of false information.
Quantifying the Signal: Methodological Rigor
Google Trends data was utilized to quantify fluctuations in search interest over time, employing Relative Search Volume as the primary metric. Relative Search Volume normalizes search data to a 0-100 scale, representing the proportion of total searches for a given term compared to its highest point in the selected time range. This normalization process allows for meaningful comparisons of search interest across different terms and time periods, mitigating the influence of overall search volume increases. Data was collected using the Google Trends API, focusing on keyword searches related to core physics concepts. The resulting time series data of Relative Search Volume provided a quantifiable basis for analyzing trends in public interest towards these topics.
Academic Cycling was incorporated into the analysis to address predictable fluctuations in search volume correlated with the academic calendar. This methodology acknowledges that search interest in educational topics predictably rises during school terms and declines during breaks. The strength of this correlation was consistently high, as demonstrated by a maintained Pearson correlation coefficient of 0.92 throughout the observed time series. This normalization process effectively removes the influence of academic schedules, allowing for more accurate identification of underlying trends in search interest independent of cyclical educational patterns.
To bolster the reliability of findings derived from Google Trends data, search volume trends were cross-referenced with corresponding Wikipedia Page View statistics. Wikipedia Page Views offer an independent, complementary metric of content consumption, functioning as a proxy for actual information seeking behavior. Correlation analysis between Google Trends Relative Search Volume and Wikipedia Page Views consistently demonstrated a statistically significant relationship, affirming that observed changes in search interest were mirrored in demonstrable content access. This validation technique mitigated potential biases inherent in relying solely on a single data source and strengthened the confidence in the reported trends.
Cross-Regional Normalization was implemented to address variations in search behavior and internet access across different geographical locations, ensuring valid comparisons of search interest over time. This process accounted for factors such as differing population sizes and search engine market share. Analysis revealed a substantial decline in Mechanics-related searches within India and South Korea; specifically, searches for the term ‘Kinetic energy’ decreased by 52.02% in these regions following normalization, indicating a potentially significant shift in educational engagement or information-seeking patterns related to this physics concept.
The Receding Horizon: Implications for Knowledge Access
A noteworthy trend indicates a decline in traditional search queries related to physics, suggesting a fundamental shift in how individuals now seek and consume scientific information. This change appears closely linked to the rising prominence of Generative AI tools, which are increasingly capable of directly answering complex questions and synthesizing information without requiring users to navigate multiple web pages. Rather than actively searching for knowledge, individuals may be leaning towards a more passive reception of information curated and delivered by these AI systems. This doesn’t necessarily signify a disinterest in physics, but rather a potential re-routing of information access – from actively seeking sources to receiving synthesized answers, potentially impacting how scientific literacy is developed and maintained in the digital age.
Generative AI tools hold significant promise for democratizing access to scientific knowledge by overcoming language barriers. Traditionally, individuals reliant on translations, or limited by their non-native proficiency in languages like English – the predominant language of scientific publication – faced considerable hurdles in engaging with research. These tools are now capable of rapidly and accurately translating complex scientific texts, allowing researchers, students, and enthusiasts worldwide to access and understand information regardless of its original language. This improved accessibility isn’t simply about translation; it extends to the potential for generating summaries and explanations in multiple languages, tailored to different levels of expertise, thus broadening participation in the scientific community and fostering global collaboration. The implications extend beyond research, empowering a more informed public and facilitating science communication across diverse linguistic landscapes.
The sheer volume of scientific data generated daily presents an unprecedented challenge to knowledge acquisition, demanding a skillset beyond simple information retrieval. Increasingly, the ability to effectively synthesize information from diverse and often conflicting sources is becoming paramount. GenAI tools excel at this complex task, identifying patterns, resolving discrepancies, and constructing coherent understandings from fragmented data – a capability that transcends traditional search methods. This shift isn’t merely about accessing more information, but about processing and integrating it meaningfully, allowing researchers and the public alike to navigate the intricate landscape of modern knowledge with greater efficiency and accuracy. The core competency now lies not in memorization, but in discerning reliable insights from the flood of available data, a task for which GenAI is uniquely positioned to assist.
The increasing prevalence of generative AI tools necessitates a fundamental shift in educational and research approaches. Rather than solely emphasizing the acquisition of facts, the focus must evolve towards cultivating critical thinking skills – the ability to evaluate information, identify biases, and synthesize knowledge from diverse sources. Researchers and educators are now tasked with designing strategies that not only leverage the power of AI for information access but also equip individuals with the tools to responsibly navigate its outputs. This includes fostering a deeper understanding of AI limitations, promoting source verification, and encouraging a nuanced approach to information consumption, ensuring that these powerful tools augment, rather than replace, human intellect and discernment.
The study reveals a curious adaptation within the ecosystem of physics information-seeking. As traditional search volume wanes with the rise of Generative AI, it isn’t simply a replacement, but a restructuring. Every dependency-in this case, the reliance on keyword-based searches-is a promise made to the past. The data suggests a move toward synthesized answers, a phenomenon echoing the idea that everything built will one day start fixing itself. This isn’t about control over information; control is an illusion demanding SLAs. Rather, it’s about a system evolving to meet new demands, mirroring the cyclical nature of learning and adaptation. As highlighted in the analysis of academic calendar impacts, the system reshapes itself around the rhythms of inquiry.
The Silent Curriculum
The observed attenuation of traditional search queries is not merely a displacement, but a symptom. It signals a migration from seeking answers to soliciting narratives. The system doesn’t simply yield information; it constructs understanding, and increasingly, that construction happens within the closed garden of generative models. The study reveals a shift, but not a resolution. It begs the question: what is lost when the friction of searching – the accidental discoveries, the cross-referencing, the necessity of critical evaluation – is smoothed away by algorithmic fluency?
The correlation with regions embracing Generative AI tools is unsettlingly neat. It implies a reshaping of cognitive habits, a delegation of intellectual labor. The long-term consequences are, of course, unknowable. But the very act of quantifying this shift establishes a baseline-a digital palimpsest against which future alterations can be measured. The silence in search logs is not emptiness; it is confession, a revealing of what is no longer needed to be asked.
Future work must move beyond simply tracking volume. The quality of engagement – the depth of inquiry, the diversity of sources – is the true metric. The system will not be built; it will be grown, a tangled ecosystem of prompts and responses. And when the system is silent, it is not resting. It is plotting-refining its understanding of what questions are no longer worth asking.
Original article: https://arxiv.org/pdf/2602.09550.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Every Creepy Clown in American Horror Story Ranked
- 22 actors who were almost James Bond – and why they missed out on playing 007
- Hazbin Hotel Secretly Suggests Vox Helped Create One of the Most Infamous Cults in History
- As Dougal and friends turn 60, Radio Times explores the magic behind The Magic Roundabout
- Jason Statham’s Hit Creature Feature Is Heading to Streaming for Free
- Kingdom Come: Deliverance 2 – Legacy of the Forge DLC Review – Cozy Crafting
- Everything We Know About Gen V Season 3 (& Why It’ll Be a Very Different Show)
- Jack Osbourne Shares Heartbreaking Tribute to Late Dad Ozzy Osbourne
- Arknights: Endfield – Everything You Need to Know Before You Jump In
2026-02-11 22:09