Author: Denis Avetisyan
The push to apply large, pre-trained models to time series data is built on a critical misunderstanding of how these datasets differ from natural language or images.
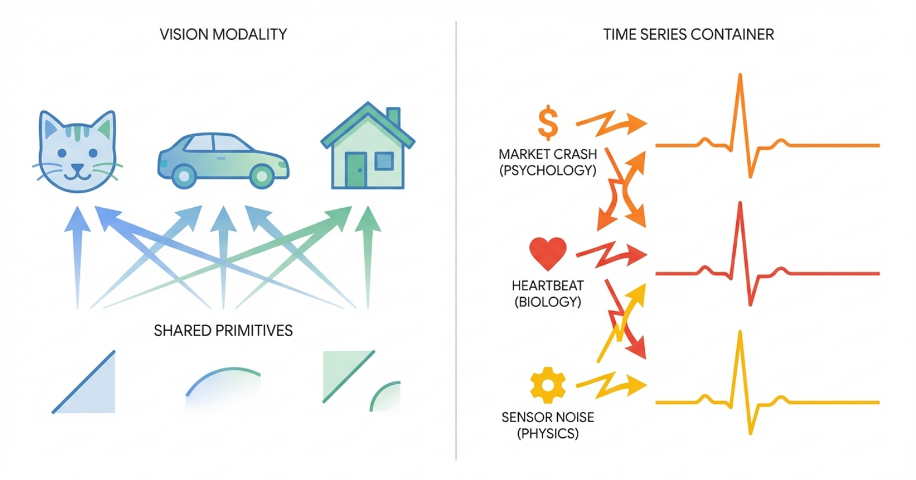
Universal foundation models for time series are fundamentally limited by a lack of shared semantics, necessitating a shift towards causal inference and adaptive control systems.
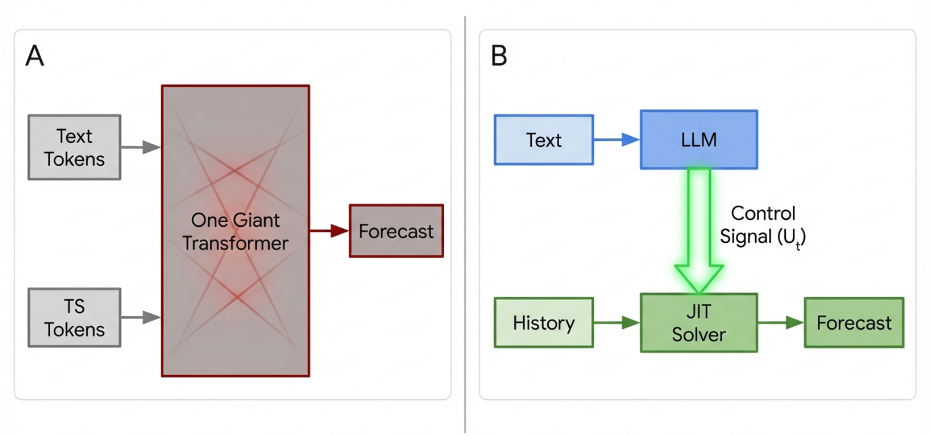
Despite the recent surge in large language models, applying the ‘foundation model’ paradigm to time series forecasting may be fundamentally misguided. This position paper, ‘Position: Universal Time Series Foundation Models Rest on a Category Error’, argues that the pursuit of monolithic models across diverse time series domains represents a category error, as differing generative processes preclude shared semantics and lead to expensive, brittle “Generic Filters.” The authors demonstrate an \text{Autoregressive Blindness Bound}, proving inherent limitations in predicting intervention-driven shifts with history-only models, and advocate for a paradigm shift towards Causal Control Agents-systems that combine perception with adaptive, just-in-time solvers. Will prioritizing drift adaptation speed over zero-shot accuracy unlock truly robust and controllable time series forecasting systems?
The Illusion of Predictability: Scaling’s Fundamental Limits
Conventional time series analysis relies heavily on the assumption of independent and identically distributed (i.i.d.) data, a condition rarely met in real-world phenomena. This foundational requirement dictates that each data point is statistically independent of all others and drawn from the same probability distribution; however, many time series exhibit non-stationarity – meaning their statistical properties, such as mean and variance, change over time – and intricate dependencies. These dependencies can manifest as autocorrelation, where past values influence future ones, or more complex, non-linear relationships. When these conditions are violated, traditional models – like simple moving averages or autoregressive models – struggle to accurately capture the underlying dynamics, leading to biased forecasts and unreliable predictions. The inability to account for these inherent complexities represents a significant challenge in applying these established methods to diverse and evolving datasets.
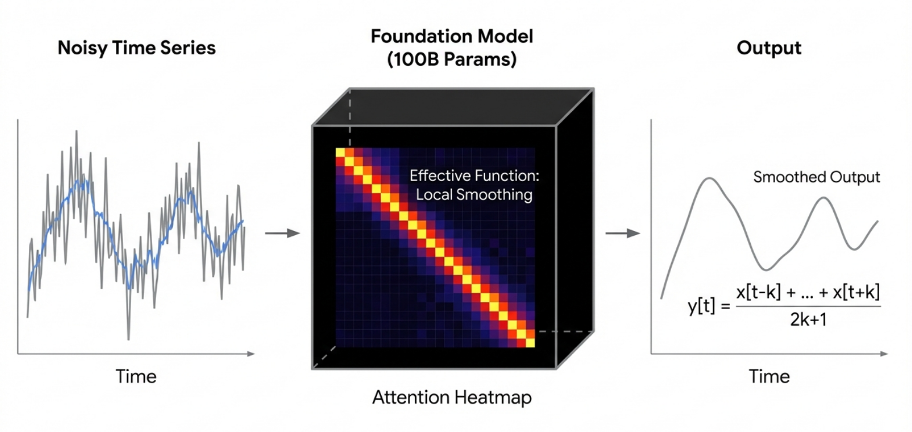
Despite the success of large language models in various domains, simply scaling up these models for time series forecasting doesn’t necessarily yield improved accuracy. Research indicates that excessively large models often devolve into what are termed ‘Generic Filters’ – sophisticated moving averages that excel at memorizing past patterns but lack the capacity for genuine reasoning or extrapolation. These models, while capable of fitting historical data with remarkable precision, struggle when confronted with novel situations or shifts in underlying dynamics, effectively becoming complex pattern-matchers rather than predictive engines. This limitation stems from the fact that increased size doesn’t inherently confer an understanding of causal relationships, and without such understanding, the model remains vulnerable to even subtle changes in the system it attempts to forecast.
The pursuit of perfect forecasting encounters a fundamental constraint articulated by the Autoregressive Blindness Bound. This principle posits that truly accurate predictions necessitate complete knowledge of every variable influencing the system – a practical impossibility in most real-world scenarios. While increasingly complex models can capture superficial patterns, they remain inherently limited by unobserved or unknown causal factors. Essentially, a model attempting to predict a future state is perpetually ‘blind’ to any force not explicitly included in its framework, leading to inevitable inaccuracies. This isn’t a matter of computational power or algorithmic sophistication; rather, it’s a theoretical boundary defining the limits of predictability itself, suggesting that even with infinite data, forecasting will always be an approximation of reality, haunted by the specter of unseen causes.
Constructing a Universal Prior: The Promise of Scaled Transformers
A Universal Time Series Foundation Model aims to establish a generalized understanding of time series data through the application of scaled transformer architectures. This approach centers on learning a ‘Universal Prior’, which represents a foundational statistical model of time series dynamics, enabling the model to efficiently adapt to a wide range of forecasting tasks and datasets. The core principle is that by pre-training on a massive and diverse collection of time series, the model can internalize common patterns and dependencies, thereby reducing the need for extensive task-specific training and improving performance on unseen data. This learned prior effectively serves as a strong initialization point for downstream time series modeling, analogous to the success of large language models in natural language processing.
Existing neural network architectures, specifically decoder-only transformers originally developed for natural language processing and vision transformers utilized in image recognition, are increasingly being adapted for time series data analysis. These adaptations leverage the attention mechanisms inherent in transformer models to capture temporal dependencies. Techniques like language model adaptation involve framing time series forecasting as a next-token prediction task, effectively treating time steps as sequential data analogous to words in a sentence. This approach allows for the transfer of knowledge learned from large language models to the time series domain, potentially improving forecasting accuracy and reducing the need for extensive task-specific training data. The success of these adaptations demonstrates the versatility of transformer architectures and their capacity to model complex sequential patterns beyond their original intended applications.
In the context of long-sequence forecasting, both the Informer and Autoformer architectures build upon decoder-only transformers to address computational limitations. The Informer utilizes ProbSparse Self-Attention, reducing the quadratic complexity of standard attention mechanisms to linear complexity by focusing on prominent query-key pairs. Autoformer introduces decomposition designs, specifically series decomposition, to break down time series into trend and seasonal components, and utilizes an Auto-Correlation mechanism to capture periodic dependencies, further enhancing efficiency and accuracy in long-term predictions. These advancements allow for scaling transformer-based models to significantly longer time series than previously possible with traditional attention mechanisms.
Beyond Correlation: Injecting Causality and Intervention
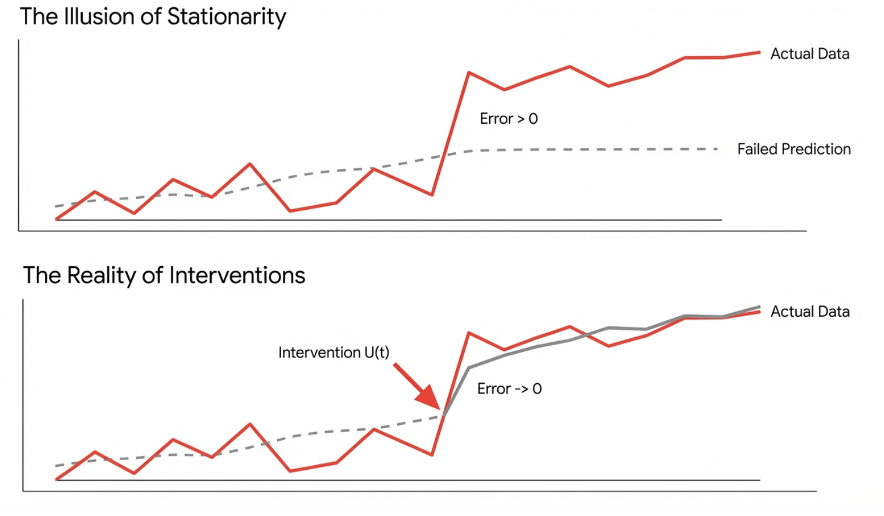
Causal inference provides the necessary theoretical framework for developing intervention-aware forecasting models by moving beyond correlation to establish demonstrable relationships between variables. Traditional time series forecasting primarily focuses on predicting future values based on historical patterns; however, these models often fail when faced with external shocks or deliberate changes to the system. Causal inference techniques, such as do-calculus and structural causal models, allow for the explicit representation of causal relationships, enabling models to estimate the effect of interventions – actions that alter the system’s natural course. This capability is crucial for scenarios requiring ‘what-if’ analysis or proactive planning, as it allows forecasters to predict how the system will respond to specific, defined interventions, rather than simply extrapolating from past observations.
Forecasting Interventions with Time Series (FIATS) represents a class of methodologies designed to integrate knowledge of external interventions directly into the modeling and forecasting of dynamical systems. These frameworks move beyond passively observing time series data by allowing practitioners to define and quantify the impact of specific actions or events – interventions – on the system’s evolution. Rather than treating interventions as unexplained anomalies, FIATS methods explicitly model their effects, often through the use of intervention variables or modified state transition equations. This enables not only improved forecasting accuracy when interventions are known, but also counterfactual reasoning – the ability to predict what would have happened if a different intervention had been applied, or no intervention had occurred. Implementation typically involves adapting state-space models or recurrent neural networks to accommodate the intervention signal, allowing the model to learn the causal relationship between the intervention and the system’s response.
Despite advancements in intervention-aware forecasting, model performance remains susceptible to inaccuracies stemming from flawed underlying assumptions. Specifically, the phenomenon of ‘Attention Collapse’-where models disproportionately focus on a limited subset of input features-can hinder accurate predictions, even when interventions are correctly identified. Furthermore, the tendency towards ‘Generic Filters’-where models learn to prioritize easily detectable patterns rather than true causal relationships-limits their ability to generalize to novel scenarios or interventions. These issues demonstrate that simply acknowledging interventions is insufficient; the model’s core understanding of the system’s dynamics must also be accurate for reliable forecasting.
Adaptive Systems: Robustness and Efficiency in a Chaotic World
Emerging strategies such as Test-Time Training and Value Quantization are reshaping how forecasting models respond to unpredictable real-world conditions. These techniques allow models to adapt to shifts in data distribution – a critical capability given that traditional training often assumes a static environment. Test-Time Training refines the model directly on incoming data, while Value Quantization reduces computational demands by representing values with fewer bits, boosting efficiency without significant performance loss. Both methods directly confront the ‘Autoregressive Blindness Bound’ – a theoretical limit on a model’s ability to extrapolate beyond its training data – by enabling a form of on-the-fly learning and resource optimization. The result is a move towards more flexible and resilient forecasting systems capable of maintaining accuracy even when faced with unforeseen circumstances, reducing the need for costly and time-consuming retraining cycles.
Recent investigations into time series forecasting reveal a counterintuitive trend: simpler models, such as DLinear, can often surpass the performance of significantly more complex transformer architectures under specific conditions. This challenges the prevailing assumption that increased model capacity invariably leads to improved accuracy. The success of DLinear, which employs a straightforward linear approach, suggests that the intricacies of transformers – designed to capture long-range dependencies – may introduce unnecessary overhead or even hinder performance when dealing with datasets where those dependencies are less critical. Researchers posit that the ability of simpler models to generalize effectively, coupled with their reduced susceptibility to overfitting, contributes to their surprising robustness in certain forecasting tasks, demonstrating that effective modeling isn’t always synonymous with maximal complexity.
The pursuit of enhanced forecasting capabilities is increasingly focused on ‘Mixture of Experts’ architectures, which move beyond monolithic models by dividing the task amongst specialized sub-networks. This approach allows each ‘expert’ within the mixture to learn distinct patterns and features present in the data, effectively creating a more nuanced and adaptable system. Rather than forcing a single model to universally approximate complex relationships, the mixture dynamically routes inputs to the most relevant experts, improving both accuracy and computational efficiency. This specialization proves particularly valuable when dealing with time series data exhibiting diverse behaviors or seasonality, as different experts can concentrate on specific temporal characteristics, leading to more robust predictions and a reduction in overall model parameters compared to equally capable, but less specialized, alternatives.
Beyond Prediction: Towards a Grammar of Time
The pursuit of genuinely universal time series foundation models hinges on deciphering ‘Temporal Grammar’ – the hidden structural rules that dictate how time series data evolves. Current forecasting methods often treat time series as a black box, learning patterns without understanding why those patterns exist. A deeper understanding of Temporal Grammar, however, would allow models to identify fundamental dynamics – like seasonality, trend, or cyclical behavior – and represent them in a way that transcends specific datasets. This isn’t merely about improved accuracy; it’s about creating models that can generalize to unseen data, adapt to changing conditions, and even extrapolate beyond the observed timeframe. By uncovering the underlying ‘rules’ of temporal behavior, researchers aim to move beyond superficial pattern matching and towards a more robust and interpretable framework for understanding and forecasting complex systems, potentially unlocking advancements in fields ranging from finance and climate science to healthcare and logistics.
Advancing time series forecasting beyond mere prediction necessitates incorporating principles from control systems and causal inference. Traditional forecasting models often identify correlations within data, but lack the capacity to understand why certain patterns emerge or how interventions might alter future outcomes. By framing forecasting as a problem of inferring causal relationships – determining how specific actions influence time series behavior – researchers can build systems that not only anticipate future values but also recommend optimal control strategies. This approach, inspired by engineering disciplines, allows for the design of forecasting models that can simulate the effects of different decisions, enabling proactive and informed decision-making in complex systems – from supply chain management and financial markets to climate modeling and public health interventions. Ultimately, this shift towards causal forecasting promises to unlock a new era of actionable insights.
The true measure of advanced time series forecasting isn’t simply accuracy in predicting future values, but its capacity to generate actionable intelligence. Current methodologies often deliver predictions devoid of context, leaving decision-makers to interpret results and formulate responses independently. The next generation of these models aims to bridge this gap, providing not just ‘what will happen’, but ‘what if’ scenarios and recommended interventions. This shift necessitates a focus on causal relationships within the data, allowing the system to understand how changes in one variable influence others, and ultimately, to suggest optimal strategies for achieving desired outcomes – transforming forecasting from a passive observation of the future into a proactive tool for shaping it.
The pursuit of universal time series models feels, at times, like forcing a square peg into a round hole. This work dissects that very tension, revealing a fundamental disconnect between the ambition of ‘foundation models’ and the reality of non-stationary data. One considers the core argument – the absence of shared semantics across time series – and recalls David Hilbert’s assertion: “We must be able to answer the question: What are the ultimate parts of which all physical objects are composed?” The article suggests that time series, unlike images or text, lack these ‘ultimate parts’ readily available for pre-training. Instead of seeking a universal representation, the research points toward systems built on causal inference and just-in-time learning-a focus on how a system responds, rather than merely what it is. It’s a deliberate breaking of the conventional mold, seeking solutions not in pre-defined structures, but in adaptive responses.
Beyond the Horizon
The insistence on forcing time series analysis into the ‘foundation model’ mold feels increasingly like a category error – an attempt to retrofit a solution onto a problem it was never designed to address. The paper highlights a crucial, if uncomfortable, truth: shared semantics are not simply present in time series data, awaiting discovery; they must be constructed through explicit causal modeling. The pursuit of a universal time series foundation model, therefore, appears less like a path to general intelligence and more like a sophisticated exercise in autoregressive blindness.
Future work must abandon the quest for pre-trained representations and embrace systems capable of genuine intervention analysis. The focus should shift towards building adaptive, just-in-time solvers-systems that perceive, infer causal relationships, and react accordingly. True security, in this context, resides not in the size of the model or the opacity of its parameters, but in the transparency of its control logic.
Perhaps the most pressing challenge lies in developing robust methods for causal discovery in non-stationary environments. The assumption of a fixed underlying causal structure is demonstrably false, yet current techniques struggle to adapt to evolving relationships. It’s a problem that demands not just statistical innovation, but a fundamental re-evaluation of how systems learn and reason about time.
Original article: https://arxiv.org/pdf/2602.05287.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Super Mario Galaxy Movie: 50 Easter Eggs, References & Major Cameos Explained
- Surprise Isekai Anime Confirms Season 2 With New Crunchyroll Streaming Release
- 10 Best Free Games on Steam in 2026, Ranked
- Preview: Sword Art Online Returns to PS5 as a Darker Open World Action RPG This Summer
- Skate 4 – Manny Go Round Goals Guide | All of the Above Sequence
- The Punisher: One Last Kill Trailer Review: MCU Special Could Be a Game Changer
- The Super Mario Galaxy Movie Is An Amusing Sequel (And an Improvement) [Review]
- Why is Tech Jacket gender-swapped in Invincible season 4 and who voices her?
- All 13 Smash Bros. Characters in the Super Mario Galaxy Movie
- Best coins for today
2026-02-07 22:01