
As an observer, I’ve come across Ollama – a user-friendly platform that allows for exploring Large Language Models (LLMs) in the context of local AI projects directly on your personal computer. However, it should be noted that Ollama necessitates the availability of a dedicated Graphics Processing Unit (GPU).
In contrast to gaming, the choice here might deviate slightly. Interestingly, it could be more enjoyable to work with local AI using an older model like the RTX 3090 as opposed to a newer one such as the RTX 5080.
In terms of games, the newer card is definitely a stronger choice. However, when it comes to Artificial Intelligence tasks, the older model holds a distinct advantage due to its larger memory capacity.
VRAM is king if you want to run LLMs on your PC

Even though the computing power of newer-generation GPUs might be superior, if they lack sufficient VRAM, their potential is not fully utilized for local AI tasks. In simpler terms, having a powerful GPU without enough video memory is like owning a high-performance car with an empty gas tank – it can’t run effectively.
In simpler terms, the new RTX 5060 graphics card is more suitable for gaming compared to the old RTX 3060. However, because the new model comes with 8GB of video memory (VRAM), while the older one has 12GB, it’s not as efficient when it comes to artificial intelligence tasks.
When using Ollama, you aim to fully load the LLM into its high-speed VRAM for optimal performance. If it exceeds this capacity, some data will overflow into your system memory, causing your CPU to handle additional work. In such cases, performance significantly decreases.
When working with LM Studio instead of Ollama, the same principle applies: It’s beneficial to allocate as much memory to the GPU as you can to load the large language model (LLM) effectively, thus reducing the need for the CPU to intervene.
GPU + GPU memory is the key recipe for maximum performance.
A simple way to determine the amount of VRAM you might require is by considering the size of your model. For instance, on Ollama’s gpt-oss:20b, it occupies 13GB when installed, so making sure you have sufficient memory to accommodate that amount should be a minimum requirement for smooth operation.
It’s beneficial to have some extra space (a buffer), especially when dealing with larger tasks and context windows, as they require time to load into the KV cache. Some suggest multiplying the size of your model by 1.2 to get a rough idea of the VRAM you should aim for. In simpler terms, this means increasing the amount of Video Random Access Memory (VRAM) you need based on your model’s size.
This same principle applies if you’re reserving memory for the iGPU to use in LM Studio, too.
Without enough VRAM, performance will tank
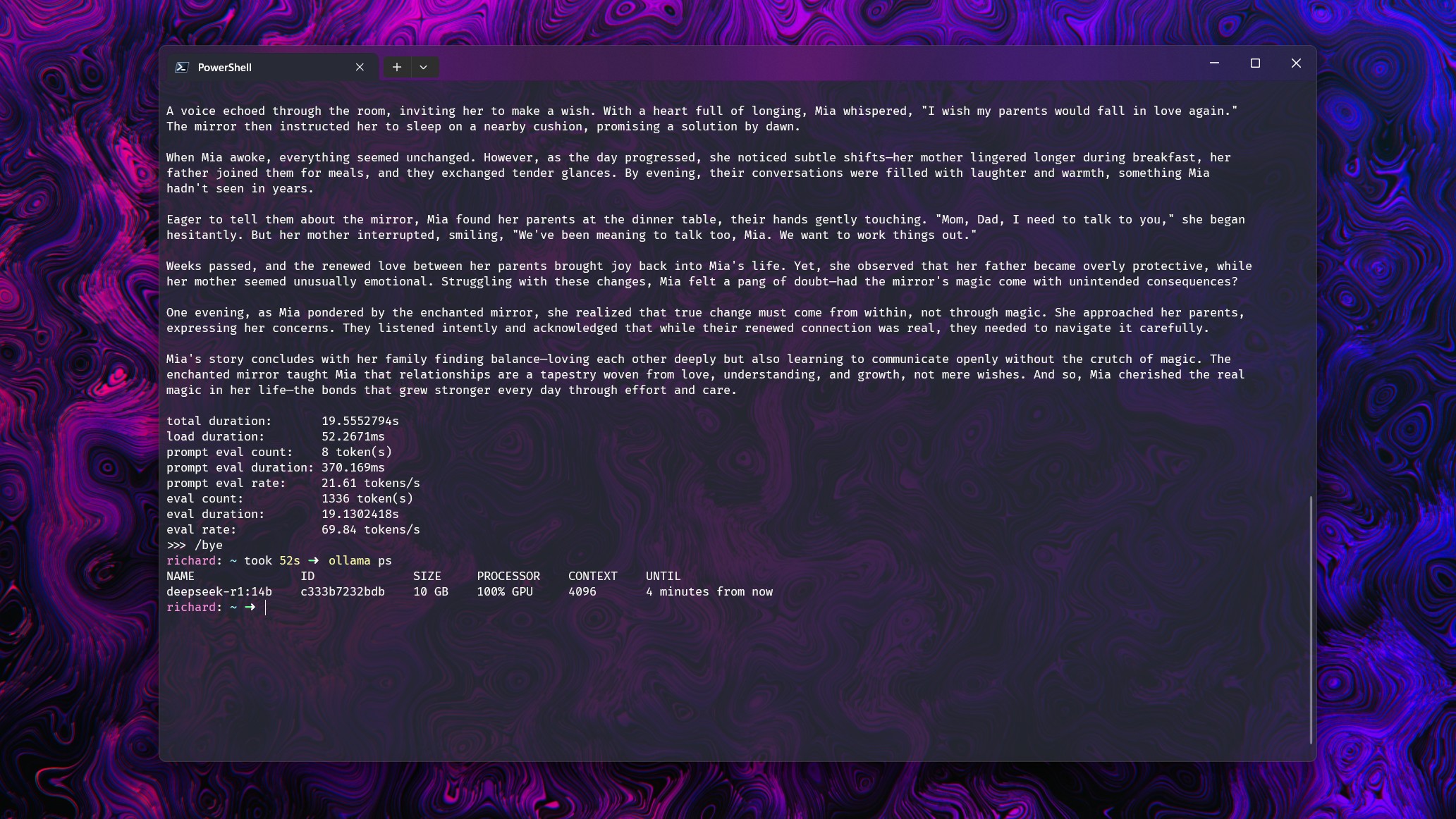
Let’s dive right into some examples! To help clarify my point, I decided to test various models with a basic prompt: “Tell me a short story.” I executed this command on multiple models using an RTX 5080 graphics card. Each of the models could be fully loaded within the 16GB VRAM allocated to them.
The rest of the system contains an Intel Core i7-14700k and 32GB DDR5 6600 RAM.
To ensure that Ollama utilized more than just its allocated memory and processing power, I expanded the context window for each model. This demonstrates the significant drop in performance when it’s pushed beyond its limits. Now, let’s delve into the numerical details.
- Deepseek-r1 14b (9GB): With a context window of up to 16k GPU usage is 100% at around 70 tokens per second. At 32k there is a split of 21% CPU to 79% GPU, with performance dropping to 19.2 tokens per second.
- gpt-oss 20b (13GB): With a context window of up to 8k GPU usage is 100% at around 128 tokens per second. At 16k there is a split of 7% CPU to 93% GPU with performance dropping to 50.5 tokens per second.
- Gemma 3 12b (8.1GB): With a context window of up to 32k GPU usage is 100% at around 71 tokens per second. At 32k there is a split of 16% CPU to 84% GPU with performance dropping to 39 tokens per second.
- Llama 3.2 Vision (7.8GB): With a context window of up to 16k GPU usage is 100% at around 120 tokens per second. At 32k there is a split of 29% CPU and 71% GPU with performance dropping to 68 tokens per second.
This testing doesn’t delve deeply into scientific analysis of these models. Instead, it serves to make a particular point clear. When a GPU can’t handle all the workload alone and other components of your PC get involved, the performance of your Language Learning Models (LLMs) drops significantly.
This brief exercise aims to highlight the significance of sufficient GPU memory for optimal performance of your Language Models (LLMs). It’s preferable to minimize the CPU and RAM taking on additional tasks whenever possible.
In this paraphrase, I used simpler language and clarified that the focus is on Language Models (LLMs) rather than just “your LLMs.” Additionally, I rephrased “picking up the slack” as “taking on additional tasks” to make it more understandable.
In simpler terms, despite what occurred, the performance remained fairly good since we had powerful hardware supporting the graphics card.
A good suggestion would be to aim for a graphics card with at least 16GB VRAM if you plan on running models up to gpt-oss:20b. If you anticipate heavier workloads, opting for a 24GB VRAM might be more suitable, and this can be achieved affordably with two RTX 3060s. Ultimately, the choice depends on your specific needs.
Read More
- 4 TV Shows To Watch While You Wait for Wednesday Season 3
- Gold Rate Forecast
- 40 Inspiring Optimus Prime Quotes
- Every Creepy Clown in American Horror Story Ranked
- PlayStation Plus Game Catalog and Classics Catalog lineup for July 2025 announced
- 10 Most Memorable Batman Covers
- 10 Best Buffy the Vampire Slayer Characters Ranked
- Best X-Men Movies (September 2025)
- All 6 Takopi’s Original Sin Episodes, Ranked
- 10 Best Connie Episodes of King of the Hill
2025-08-25 17:10