
Lately, I’ve been experimenting more by running Language Models (LLMs) directly on my computer, and for the majority of the time, I’ve been using Ollama for this purpose.
The Ollama tool is an exceptional resource that simplifies the process of downloading and operating LLMs directly on your personal computer, with the latest GUI application making it even more user-friendly. This tool seamlessly integrates into your workflow, however, it does have a significant drawback.
If you lack a specialized graphics processing unit (GPU), its performance may not be impressive. I’ve been utilizing it with an RTX 5080, and it performs exceptionally well, but when compared to a device like the newly arrived Geekom A9 Max mini PC, which is under review, the experience is significantly different.
Ollama doesn’t offer official compatibility with integrated graphics on Windows systems. By design, it primarily relies on the CPU. In some instances, I prefer not to explore alternative solutions.
Instead, opt for LM Studio, where you can easily harness the power of built-in GPUs without much hassle. In mere seconds, I can do it, and it’s exactly what I recommend you to try, as it’s superior to Ollama when it comes to utilizing your integrated GPU.
What is LM Studio?
On your Windows computer, LM Studio serves as another tool for acquiring LLMs (Language Learning Models) and tinkering with them. While it operates slightly distinctly compared to Ollama, the fundamental outcome remains consistent.
The new version boasts a noticeably more sophisticated graphical user interface compared to the original Ollama app, making it an even stronger choice. To fully leverage Ollama beyond the terminal, you might want to consider using additional tools like OpenWebUI or the Page Assist browser extension.
This platform serves as a comprehensive solution where users can discover, install models, and engage with them through an intuitive, chat-like interface. Although there are numerous sophisticated features available, we will initially keep things straightforward for ease of use.
A notable advantage is that LM Studio incorporates Vulkan, allowing you to transfer models onto both AMD and Intel’s integrated GPUs for computational tasks. This is significant since my tests have consistently shown that using the GPU rather than the CPU results in faster performance.
So, how do you use an integrated GPU in LM Studio?
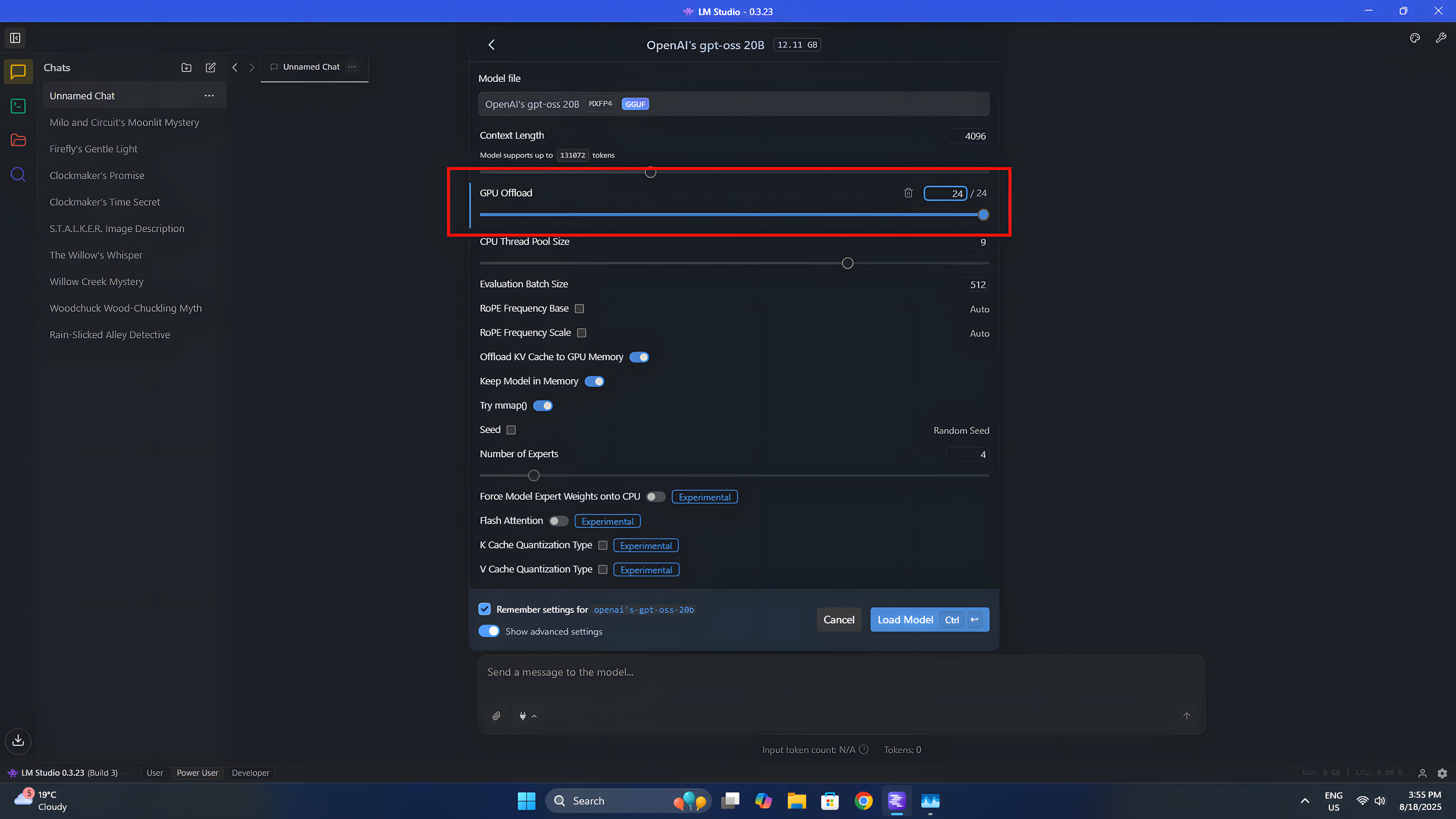
Another advantage when choosing the LM Studio is that using your integrated graphics processor (iGPU) with an LLM doesn’t require any complex or technical setup procedures.
To employ the model, all you need to do is pick the desired option from the drop-down menu at the top. Once selected, several settings will become available. In our case, we’ll primarily focus on the offloading to GPU.
The system operates using a progressive approach, where each step is like a building block contributing to the overall process. These blocks, or layers, are integral to the functioning of the Large Language Model (LLM). As instructions move down through these layers sequentially, it culminates with the last layer generating the response. You can choose to delegate tasks across all layers; however, if you opt for fewer layers, your CPU will take on some additional responsibilities to complete the task.
After you feel satisfied with the settings, go ahead and click on “Load Model”. This action will store the model in your device’s memory and allow it to function according to the specified limits you’ve set.

On the Geekom A9 Max, which features Radeon 890M integrated graphics, I aim to utilize its entire capability. Since I’m not using this device for gaming when working with AI, I prefer the GPU to be fully dedicated to the Large Language Model (LLM). To accomplish this, I reserve 16GB out of the system’s total memory of 32GB exclusively for the GPU, allowing it to load the model efficiently and perform optimally.
Using a model similar to gpt-oss:20b allows me to allocate its entire size to the dedicated GPU memory, utilizing the GPU for computations while keeping the system’s remaining memory and the CPU unaffected. As a result, I can process approximately 25 words or tokens per second with this setup.
Is the performance comparable to a desktop PC with an RTX 5080? Definitely not. However, when compared to using just the CPU, it is significantly faster. Plus, it avoids consuming nearly all of your CPU resources, which can be beneficial for other software on your computer. Generally speaking, the GPU is seldom busy; therefore, utilizing it seems like a smart choice.
If you want to achieve even better performance, diving deep into the details might be beneficial, but for this discussion, we’re zeroing in on LM Studio. Remarkably, if you don’t possess a dedicated GPU, LM Studio is unquestionably the go-to tool for running local Language Models (LLMs) on your system. Simply install it, and it will function seamlessly without any complications.
Read More
- Why is Tech Jacket gender-swapped in Invincible season 4 and who voices her?
- Welcome to Demon School! Iruma-kun season 4 release schedule: When are new episodes on Crunchyroll?
- Sydney Sweeney’s The Housemaid 2 Sets Streaming Release Date
- Highly Anticipated Strategy RPG Finally Sets Release Date (And It’s Soon)
- The Super Mario Galaxy Movie: 50 Easter Eggs, References & Major Cameos Explained
- Dune 3 Gets the Huge Update Fans Have Been Waiting For
- TV legend Carol Kirkwood reveals the reasons why she decided to retire after 28 years with BBC
- Who Wants to Be a Millionaire? confirms contestant wins full £1 million prize pot on Jeremy Clarkson quiz
- How Blake Lively & Ryan Reynolds’ Kids Pranked Her on April Fool’s Day
- Sesame Street Slams “Disgusting” Posts on Elmo’s Account After Hack
2025-08-19 14:40