
It seems that it’s generally thought that running AI locally on a personal computer requires more powerful hardware. While this notion holds some truth, just like with gaming, it’s a matter of degrees. You can run similar AI applications on a Steam Deck as you can on a PC equipped with an RTX 5090, albeit the experience may not be identical. However, what truly matters is that the AI tasks can still be executed effectively, regardless of the hardware differences.
It’s worth noting that even when experimenting with local AI tools, such as operating Language Models like Ollama, you don’t necessarily require a high-end GPU with large amounts of video memory to get started. While having such a setup would certainly be beneficial, it’s not an absolute requirement.
Example: Despite its relatively outdated specifications such as an AMD Ryzen 5 2500U processor, 8GB of RAM, and no dedicated graphics, my seven-year-old Huawei MateBook D is still functional. It can run Ollama and load some Large Language Models (LLMs), making it usable.
There are caveats to running AI on older hardware
In terms of current applications for artificial intelligence, gaming seems to be an ideal comparison case. To fully appreciate the newest, high-demand content, it requires powerful hardware. However, it’s also possible to enjoy numerous recent games on less advanced and less powerful systems, including those that solely use integrated graphics.
As a bystander, I’d like to point out that using older or less potent hardware might not deliver the same smoothness as you’re aiming for. Instead of striving for at least 144 frames per second (FPS), you might find yourself settling around 30 FPS. However, achieving this goal is achievable, but it comes with compromises. You may need to scale back on graphics settings, disable ray tracing, and potentially lower your resolution to optimize performance.
Just like with AI, you won’t be generating massive amounts of data at a rapid pace nor will you be using the most recent and large-scale models all the time.
While there are numerous smaller models available for experimentation, even on older hardware, I can vouch for their effectiveness. In case your GPU is suitable, it will be utilized. However, if you don’t have one, rest assured, I’ve still managed to achieve some level of success.
In simpler terms, I’ve managed to load a model with approximately 1 billion parameters, often referred to as ‘1b models’, onto an old laptop operating Fedora 42. This particular laptop doesn’t support the APU (Accelerated Processing Unit) officially under Windows 11, but since it typically runs Linux on older hardware, I do so in this case too.
Ollama works on various operating systems, including Mac, Windows, and Linux. This means it can be used regardless of the system you’re currently working with. Even older Mac models might find some compatibility with it.
So, just how ‘usable’ is it?
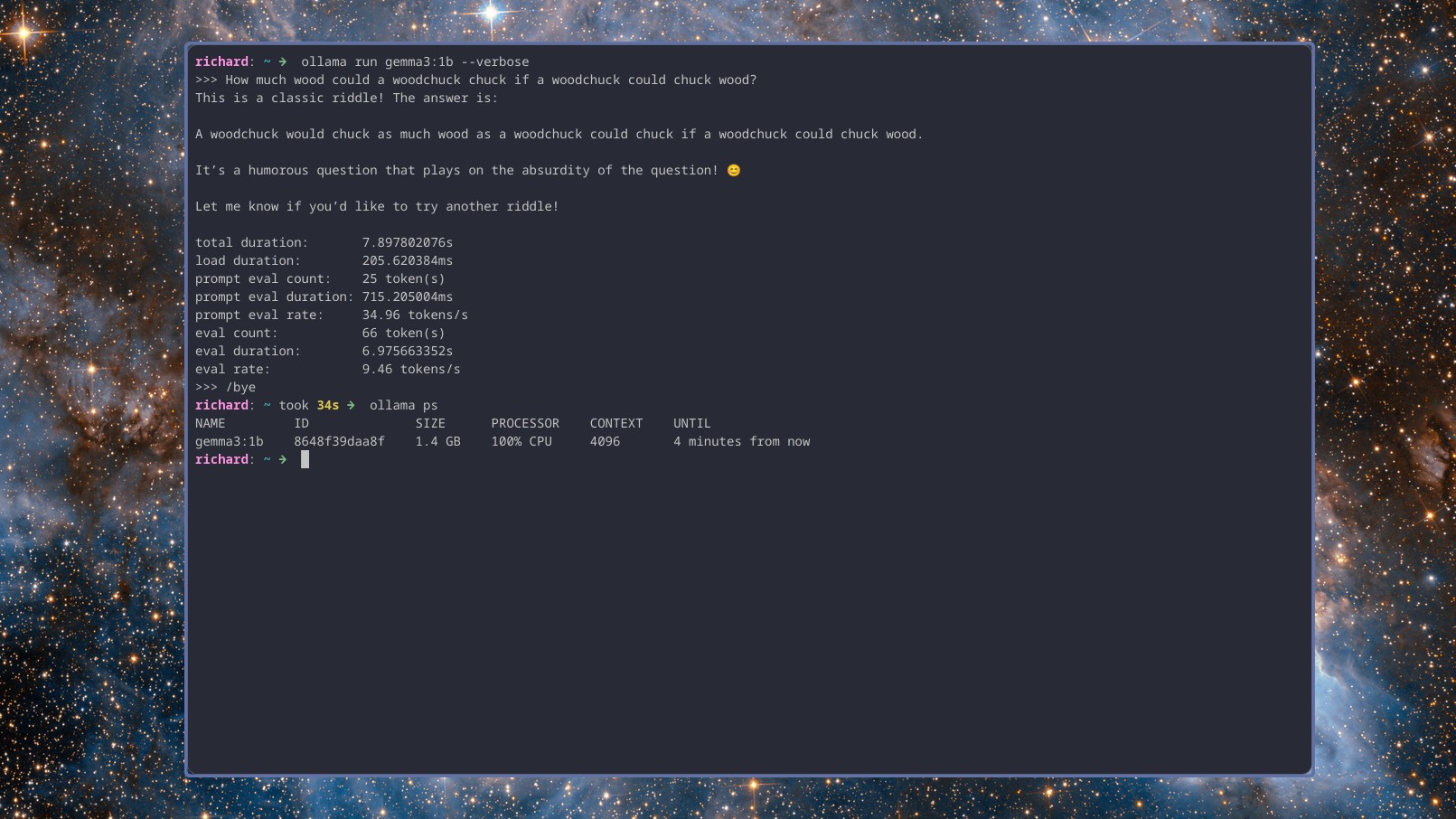
On this particular laptop, I haven’t experimented with models larger than 1 billion parameters. Frankly, I believe investing time in such experiments might not be beneficial. However, I recently tested three 1b models: gemma3:1b, llama3.2:1b, and deepseek-r1:1.5b. Interestingly, they all demonstrate comparable performance. For these language models, a 4k context length is utilized. Given the results I’ve seen, I’m hesitant to attempt anything with a larger context length.
First up is my old favorite:
“How much wood would a woodchuck chuck if a woodchuck could chuck wood?”
Here are two models, Gemma 3 and Llama 3.2, which deliver concise and swift replies, averaging nearly 10 responses per second. On the other hand, Deepseek r1, known for its reasoning abilities, takes a moment to process its thoughts before providing an answer, operating at about 8 tokens per second.
However, they might not be extremely quick, but they are functional. Notably, all of them are producing replies much more swiftly than I could type or even think up (and undoubtedly faster than I could manually input text), given the 4k context length.
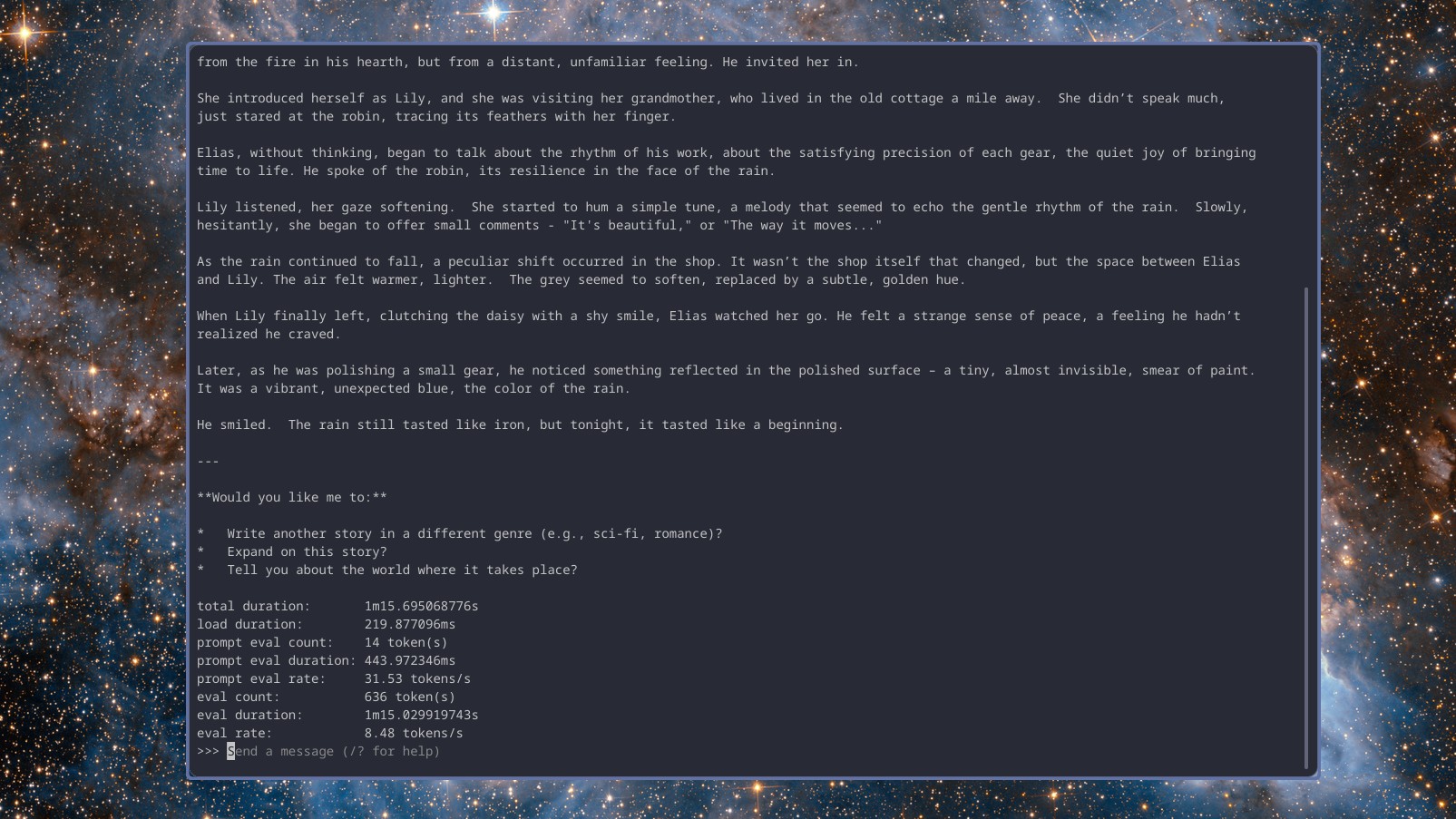
In simpler terms, the second trial involved more complex tasks. I requested each model to create a basic PowerShell script that could pull the raw content of text files from a GitHub repository, and also pose queries to ensure satisfaction with the results, thus enhancing the quality of the script.
In this case, I’ve not yet confirmed if the results are correct. However, my focus here is primarily on assessing how effectively and quickly the models can tackle the problem at hand.
Gemma 3 provided a comprehensive breakdown of the script, answering questions as instructed, and managed this task at nearly 9 words per second. DeepSeek r1, though slightly slower at around 7.5 words per second, didn’t ask questions. Llama 3.2 delivered results comparable to Gemma 3 at a pace of almost 9 words per second as well.
By the way, it’s important to note that the entire operation was run on battery power using an optimized power strategy. When these devices were plugged into an external power source, they nearly doubled the rate of token production per second and reduced the time required to finish the task by approximately half.
That aspect seems more captivating to me. With a laptop powered by battery, you can still accomplish tasks whether you’re out and about or at home/office, even if your hardware is relatively old.
This task was entirely carried out using just the computer’s processor and memory, with no additional support from the laptop’s graphics processing unit (iGPU). The laptop allocates several gigabytes of RAM for the iGPU, but even then, it’s not compatible with Ollama. Running a quick command ps for Ollama shows 100% utilization on the CPU.
You can work with these compact-sized LLMs, and it’s worth noting that you don’t have to invest in expensive, high-end hardware to do so; instead, you can experiment, incorporate them into your workflow, and even pick up new skills – all while keeping costs under control.
On YouTube, it’s not hard to come across creators utilizing AI on Raspberry Pi or home servers built from relatively affordable and now inexpensive older hardware. With a moderately priced, older laptop, you might even be able to begin your own AI journey.
It’s not ChatGPT, but it’s something. Even an old PC can be an AI PC.
Read More
- The Super Mario Galaxy Movie: 50 Easter Eggs, References & Major Cameos Explained
- 10 Best Free Games on Steam in 2026, Ranked
- All 13 Smash Bros. Characters in the Super Mario Galaxy Movie
- Dune 3 Gets the Huge Update Fans Have Been Waiting For
- Control Resonant’s Hiss and Mold Are “Way More Complex” Than Before (and More Aggressive)
- Welcome to Demon School! Iruma-kun season 4 release schedule: When are new episodes on Crunchyroll?
- Highly Anticipated Strategy RPG Finally Sets Release Date (And It’s Soon)
- TV legend Carol Kirkwood reveals the reasons why she decided to retire after 28 years with BBC
- Sydney Sweeney’s The Housemaid 2 Sets Streaming Release Date
- Why is Tech Jacket gender-swapped in Invincible season 4 and who voices her?
2025-08-13 14:14