Author: Denis Avetisyan
A new framework balances the speed of adaptive experimentation with the rigor of statistical validation, leading to more reliable scientific findings.
This work presents a statistically reliable optimization framework for multi-armed bandit experiments, addressing the reward-inference tradeoff and improving experimental design.
Traditional scientific experimentation often relies on uniform sampling, potentially overlooking opportunities to maximize information gain and accelerate discovery. This limitation motivates the work ‘A Statistically Reliable Optimization Framework for Bandit Experiments in Scientific Discovery’, which addresses the challenges of applying multi-armed bandit (MAB) algorithms-designed for adaptive sampling-to statistically rigorous hypothesis testing. We present a novel framework that corrects for biases introduced by adaptive sampling and introduces an objective function balancing cumulative reward with statistical power, enabling practitioners to select optimal bandit algorithms based on problem-specific costs. Could this approach unlock a new paradigm for efficient and reliable scientific exploration across diverse domains?
The Illusion of Stability: Why Traditional Experiments Fail
Conventional experimental designs frequently operate under the assumption of stable conditions, a limitation that significantly diminishes their effectiveness when applied to real-world scenarios characterized by constant flux. This static approach struggles to accommodate environments where underlying parameters shift over time, leading to suboptimal decisions and inaccurate conclusions. For instance, a drug trial designed with fixed dosages might fail to account for patient responses that evolve throughout the study, or a marketing campaign optimized for a specific demographic may quickly become irrelevant as consumer preferences change. Consequently, these traditional methods often require frequent redesign and re-evaluation, proving both costly and inefficient in dynamic settings where adaptability is paramount for sustained performance and reliable insights.
Adaptive experimentation represents a significant shift from traditional, static research designs by embracing a sequential approach to decision-making. Rather than defining a fixed procedure upfront, this framework allows for real-time adjustments based on incoming data, continuously refining strategies to achieve optimal outcomes. This iterative process is particularly valuable in complex and changing environments where pre-defined protocols may quickly become ineffective. By actively learning from each observation, adaptive experiments can efficiently identify the most rewarding actions, accelerating the pace of discovery and improving performance across diverse fields, from clinical trials and marketing campaigns to engineering optimization and algorithmic development. The core principle lies in intelligently allocating resources – balancing the need to gather new information with the desire to capitalize on existing knowledge – thereby maximizing cumulative rewards over time.
Effective adaptive experimentation hinges on a delicate balance between exploration and exploitation – a core challenge in sequential decision-making. Initially, a system benefits from exploration, actively seeking new information about potentially rewarding options, even if it means temporarily sacrificing immediate gains. As data accumulates, the focus gradually shifts towards exploitation, leveraging existing knowledge to maximize returns from the most promising choices. However, a purely exploitative strategy risks becoming trapped in local optima, overlooking superior alternatives that remain undiscovered. Sophisticated algorithms, such as those employing \epsilon \$-greedy approaches or upper confidence bounds, dynamically adjust this trade-off, ensuring continued learning while consistently striving for optimal performance. This ongoing interplay between seeking new knowledge and capitalizing on current understanding is fundamental to the success of adaptive systems in dynamic and uncertain environments.</p> <p>The efficacy of adaptive experimentation hinges on a delicate balance between immediate gains and the need for robust statistical understanding. Each decision in an adaptive process presents a trade-off: choosing the option currently believed to be optimal - <i>exploitation</i> - yields the highest immediate reward, but may limit the acquisition of new information. Conversely, prioritizing exploration - deliberately selecting suboptimal options to gather data - sacrifices short-term reward for the potential of discovering even better strategies in the long run. This tension is not merely practical; it’s fundamentally statistical. Insufficient exploration can lead to biased estimates and incorrect conclusions, while excessive exploration can delay the realization of substantial benefits. Therefore, successful implementation demands algorithms and designs that carefully quantify and manage this trade-off, often employing techniques like Bayesian optimization or multi-armed bandit algorithms to intelligently allocate resources between gathering evidence and maximizing cumulative reward, ensuring both statistical validity and practical effectiveness. </p> <h2>Navigating the Trade-off: Multi-Armed Bandits as a Framework for Allocation</h2> <p>The Multi-Armed Bandit (MAB) method is a formalized approach to the exploration-exploitation dilemma in resource allocation. It frames the problem as selecting actions from a set of options - the “arms” of the bandit - where each arm yields a reward drawn from an unknown probability distribution. The objective is to maximize the cumulative reward obtained over a given time horizon. Unlike purely random allocation, MAB algorithms dynamically adjust resource distribution based on observed rewards, prioritizing options that demonstrate higher potential. This is achieved through strategies that balance gathering information about less-explored options (exploration) with leveraging knowledge of currently high-performing options (exploitation). The mathematical foundation allows for quantifiable performance metrics, such as regret - the difference between the cumulative reward of an optimal strategy and the algorithm’s actual cumulative reward - enabling rigorous comparison and optimization of allocation policies.</p> <p>Thompson Sampling is a Bayesian algorithm for the Multi-Armed Bandit problem that addresses the exploration-exploitation dilemma by maintaining a probability distribution over the expected reward of each arm. This distribution is updated after each trial using Bayesian inference; specifically, the algorithm assumes each arm’s reward is drawn from an unknown distribution, typically a Beta distribution for Bernoulli rewards or a Gaussian distribution for continuous rewards. After updating, a sample is drawn from each arm’s posterior distribution, and the arm with the highest sampled value is selected for the next trial. This approach naturally balances exploration - by sampling from distributions with high uncertainty - and exploitation - by favoring arms with high estimated rewards, without requiring an explicit parameter to control this trade-off. The algorithm’s performance is theoretically bounded, with regret growing proportionally to the logarithm of the number of trials [latex]O(\log T).
Computational efficiency in Multi-Armed Bandit (MAB) algorithms is frequently enhanced through batching and vectorization techniques. Batching involves processing multiple potential actions or ‘arms’ simultaneously, reducing the overhead associated with iterative calculations. Vectorization leverages optimized numerical libraries to perform operations on entire arrays of data - such as reward estimates or action probabilities - in parallel, rather than processing each element individually. This parallelization significantly accelerates computations, particularly for algorithms that require frequent updates to large numbers of parameters. The performance gains from these techniques are crucial when dealing with high-dimensional action spaces or real-time applications where rapid decision-making is essential.
Uniform randomization, in the context of Multi-Armed Bandit (MAB) algorithms, establishes a fundamental baseline for performance evaluation. This method involves assigning an equal probability to each available action or “arm” during the initial stages of resource allocation. By distributing trials evenly across all options, uniform randomization guarantees an unbiased sampling process, free from pre-existing preferences or assumptions. This unbiasedness is crucial for accurately assessing the improvements offered by more sophisticated MAB algorithms like Thompson Sampling or Upper Confidence Bound, as any observed gains can be confidently attributed to the algorithm’s learning and exploitation strategies rather than an initial biased distribution of resources. The resulting data from uniform randomization provides a clear point of reference against which the efficiency and cumulative reward of other MAB methods can be objectively compared.
Beyond Independence: Correcting for Bias in Adaptive Hypothesis Testing
Traditional hypothesis testing relies on the assumption of independent and identically distributed (i.i.d.) data. Adaptive experiments, by their nature, violate this assumption because the allocation of subjects to treatment groups is often modified during the experiment based on observed outcomes. This creates a dependency between observations; the treatment assigned to a later subject is conditional on the data from earlier subjects. Consequently, standard statistical tests, which calculate p-values assuming independence, will often produce inflated Type I error rates - incorrectly rejecting the null hypothesis. The correlation introduced by adaptive allocation means that observed differences between groups are more likely due to chance, rendering traditional significance testing unreliable without appropriate correction methods.
The application of traditional hypothesis testing methods to adaptive experiments introduces the potential for inflated Type I error rates due to the non-independence of observations arising from sequential decision-making. The Algorithm-Induced Test (AIT) and Adaptive Randomization Test (ART) are specifically designed to address this issue by accounting for the algorithm’s influence on data collection. AIT focuses on correcting for the selection bias introduced by the adaptive algorithm, while ART utilizes randomization principles to establish valid statistical inference. Both methods involve modifications to the test statistic or the calculation of p-values to reflect the dependence structure inherent in adaptive designs, thereby maintaining the desired statistical properties and ensuring the reliability of experimental conclusions.
Power analysis is a critical step in designing adaptive experiments to determine the minimum sample size required to detect a statistically significant effect. This analysis centers on establishing an acceptable probability of avoiding a Type II error - incorrectly failing to reject a false null hypothesis. A commonly accepted target power is 0.8, meaning there is an 80% probability of detecting a true effect if it exists. Achieving this power level necessitates careful consideration of the expected effect size, the desired significance level (alpha, typically 0.05), and the variance of the measured outcome. Simulations are frequently employed to validate the chosen sample size, ensuring sufficient statistical power under the specific conditions of the adaptive experiment and accounting for the complexities introduced by the adaptation process. Insufficient power can lead to wasted resources and inconclusive results, while excessive sample sizes are ethically problematic and inefficient.
While adaptive experiments introduce complexities to statistical inference, established techniques like Analysis of Variance (ANOVA) and Tukey’s Honestly Significant Difference (HSD) test retain utility when implemented with careful consideration of the adaptive process. These tests can be validly applied if the adaptation rules preserve independence after the data has been observed and the final test statistic is calculated on the fully observed data. Specifically, ANOVA and Tukey’s HSD are appropriate for comparing means across treatment groups in an adaptive experiment, provided the experimental design accounts for potential bias introduced by the adaptation and that assumptions of normality and equal variance are met. Adjustments to the degrees of freedom may be necessary depending on the specific adaptation strategy employed, but the core principles of these tests remain applicable for analyzing the collected data.
The Cost of Learning: Optimizing Efficiency in a Dynamic World
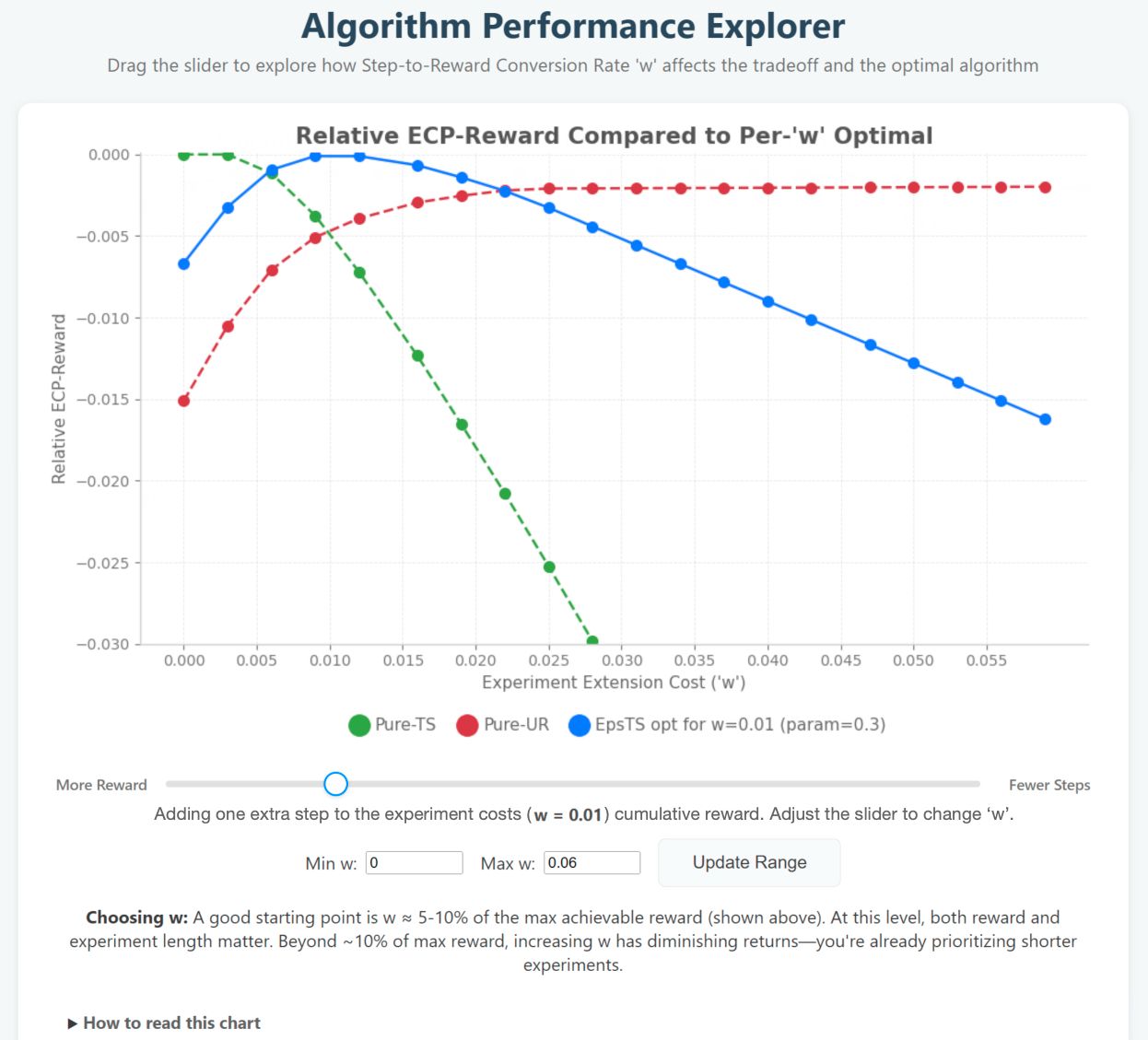
The pursuit of optimal decision-making often necessitates a balance between acquiring information and realizing immediate gains; the Experiment Cost Penalized Reward (ECP-Reward) function formalizes this crucial tradeoff. Rather than solely maximizing cumulative reward, this approach explicitly incorporates the cost associated with experimentation itself - acknowledging that each test, while potentially informative, delays the realization of benefits. By penalizing experimental actions within the reward structure, the ECP-Reward function encourages algorithms to strategically allocate resources, favoring exploitation of known advantageous options when the potential informational gain from further exploration is sufficiently small. This principled framework moves beyond simple reward maximization, enabling algorithms to learn more efficiently, particularly in environments where experimental resources are limited or costly, and fostering a more nuanced understanding of the interplay between statistical inference and reward acquisition.
In scenarios where resources are limited - be it computational power, time, or physical materials - the imperative to minimize experimental cost becomes paramount. Traditional approaches to maximizing rewards often overlook the inherent expenses associated with gathering data, leading to inefficient exploration and potentially unsustainable research practices. When budgets are tight, each experiment carries a significant weight, demanding strategies that prioritize information gain relative to its price. This focus isn’t simply about frugality; it’s about enabling continued progress even under duress, allowing researchers to extract meaningful insights from limited means and maintain the viability of long-term investigations. Ultimately, a conscientious approach to experimental cost is not a constraint, but a catalyst for innovation in resource-scarce settings.
A core challenge in experimental design lies in balancing the pursuit of immediate rewards with the necessity of gathering informative data - a tension this optimization strategy directly addresses. By explicitly considering the cost of each experiment, the approach achieves an ECP-reward score of 0.7465 when utilizing the epsilon-TS(0.3) algorithm, demonstrably exceeding the performance of both Thompson Sampling (TS) and Upper Confidence Bound (UR) methods. This improvement isn’t simply about maximizing gains; it’s about intelligently allocating resources to ensure a more robust and efficient learning process, effectively quantifying the value of information alongside direct reward attainment.
Advanced experimental designs benefit significantly from adaptive techniques that enhance efficiency and reliability. Through strategic binning and batching of null-distribution simulations, computational demands are drastically reduced - by orders of magnitude, in fact - without compromising the integrity of the results. This optimization allows for quicker iterations and broader exploration of experimental parameters, ultimately leading to more informative outcomes. Rigorous testing, with a horizon of T=200, demonstrates a remarkably low approximation error in average reward - less than 0.001 - confirming the precision and robustness of this approach, and establishing it as a valuable tool for resource-constrained research environments.
The pursuit of statistically reliable optimization, as detailed in this framework, reveals a fundamental truth about how humans attempt to navigate uncertainty. Every hypothesis is, at its core, an attempt to make uncertainty feel safe. Immanuel Kant observed, “All our knowledge begins with the senses, then proceeds to understanding.” This framework doesn't merely seek to maximize reward, but to establish a rigorous testing correction-a method for translating observed data into justifiable confidence. It acknowledges that the reward-inference tradeoff isn’t about achieving perfect prediction, but about building a system that allows for the reliable testing of assumptions, thus reducing the anxiety inherent in venturing into the unknown.
The Road Ahead
The framework presented here addresses a persistent, if often unacknowledged, truth: scientists do not seek truth, they seek confirmation. This work offers a more efficient route to that endpoint - or, more accurately, to a statistically defensible illusion of it. The correction for sequential testing is a necessary, though hardly sufficient, step. The core limitation remains the inherent difficulty in accurately modeling the ‘reward’ function itself. Humans, predictably, are terrible at assigning objective value, and any algorithm relying on subjective assessments will ultimately reflect those biases - amplified, naturally, by the optimization process.
Future iterations should focus less on statistical rigor, and more on the psychological underpinnings of experimental design. A truly adaptive system wouldn't merely optimize for statistical power, but for the experimenter’s aversion to being wrong - a far more potent, and predictable, force. The ‘reward’ isn’t the result, it’s the relief of avoiding a Type I error, the comfort of seeing a pre-conceived notion validated.
Ultimately, the goal isn’t to discover what is, but to efficiently construct a narrative that minimizes cognitive dissonance. This framework is a tool for that construction - a sophisticated means of justifying belief, not a path to objective truth. The next step isn't a better algorithm, but a better understanding of the flawed creature building it.
Original article: https://arxiv.org/pdf/2603.11267.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Best Controller Settings for ARC Raiders
- FRONT MISSION 3: Remake coming to PS5, Xbox Series, PS4, Xbox One, and PC on January 30, 2026
- Mark Zuckerberg & Wife Priscilla Chan Make Surprise Debut at Met Gala
- Meet the cast of Good Omens season 3: All the actors and characters
- 7 Great Marvel Villains Who Are Currently Dead
- Welcome to Demon School! Iruma-kun season 4 release schedule: When are new episodes on Crunchyroll?
- Nippon Sangoku Is The Best New Post-Apocalyptic Anime of Spring 2026
- Wistoria: Wand and Sword Season 2 release schedule: When are new episodes out?
- The Boys Season 5 Officially Ends An Era For Jensen Ackles’ Soldier Boy
- Khloe, Kourtney Kardashian Call Out Kylie Jenner for Mother’s Day Post
2026-03-15 21:39