Author: Denis Avetisyan
A new benchmark reveals the challenges of evaluating long-term memory in large language models and highlights limitations in current reward systems.
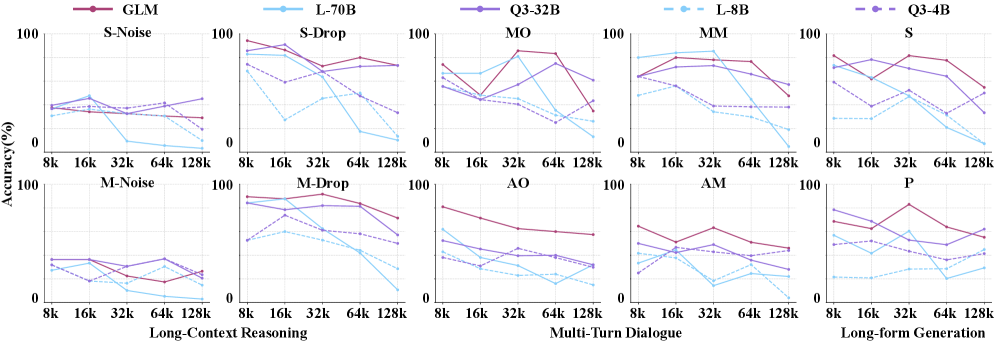
Researchers introduce MemRewardBench to assess how well reward models can judge the quality of long-term memory management in LLMs.
Effective long-context handling remains a core challenge for large language models, despite increasing reliance on memory-augmented mechanisms. To address this, we introduce $\texttt{MemoryRewardBench}$: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models, a novel benchmark designed to systematically evaluate reward models’ (RMs) ability to assess long-term memory management processes across diverse tasks and context lengths-ranging from 8K to 128K tokens. Our evaluations of 13 cutting-edge RMs reveal a narrowing performance gap between open-source and proprietary models, alongside inherent limitations in current RMs’ capacity to accurately judge LLM memory quality. How can we better align reward models with the nuanced requirements of long-context reasoning and unlock the full potential of memory-augmented LLMs?
The Limits of Sequential Thought: Confronting Long-Range Dependency
While Large Language Models demonstrate remarkable proficiency in tasks like text completion and translation, their ability to sustain meaningful context diminishes as the input sequence lengthens. This phenomenon, often referred to as the ‘long-range dependency problem’, arises because these models typically process information sequentially, making it difficult to recall and integrate details from earlier parts of a text when generating later outputs. Consequently, LLMs can exhibit a loss of coherence, introduce irrelevant information, or simply fail to maintain a consistent narrative voice over extended sequences – limiting their effectiveness in applications demanding nuanced understanding and sustained reasoning, such as writing novels, conducting in-depth analyses, or engaging in lengthy, multi-turn conversations.
The capacity of Large Language Models to sustain coherent and contextually relevant responses diminishes considerably when confronted with tasks demanding extended reasoning or intricate understanding. This presents a significant obstacle in areas such as long-form content creation – where narratives must remain consistent over thousands of words – and multi-turn dialogue systems, which require the model to accurately recall and integrate information exchanged throughout a prolonged conversation. The inability to effectively maintain context across extended sequences leads to outputs that may drift off-topic, introduce inconsistencies, or fail to leverage previously established information, ultimately limiting the model’s capacity to engage in genuinely complex and nuanced interactions.
The inherent architecture of many Large Language Models presents a significant obstacle to effective long-term memory access. These models typically process information sequentially, meaning each new piece of text is analyzed in order, relying on a ‘hidden state’ to encapsulate prior context. However, as sequences grow, this hidden state becomes a bottleneck; relevant information from the distant past can be diluted or lost entirely as it’s repeatedly transformed with each new input. This isn’t simply a matter of computational cost, but a fundamental limitation in how information is represented and retrieved. The model struggles to efficiently pinpoint and utilize crucial details from earlier parts of a lengthy conversation or document, hindering its ability to maintain coherence and perform complex reasoning that demands a robust understanding of the entire context. Consequently, innovations in memory architectures are vital to overcome this sequential processing limitation and unlock the full potential of LLMs.
The true power of Large Language Models remains largely untapped without sophisticated methods for managing long-term memory. Current architectures, while adept at processing immediate context, struggle to retain and effectively utilize information across extensive sequences-a critical limitation for applications demanding sustained reasoning and complex narrative construction. Innovations in this area aren’t simply about increasing the amount of information retained, but rather about developing mechanisms for efficient retrieval, dynamic updating, and relevant contextualization of past data. Successfully addressing this challenge promises to unlock LLM capabilities in areas like in-depth scientific analysis, intricate storytelling, and truly engaging, multi-faceted dialogue systems – moving these models beyond impressive feats of short-form generation towards genuine cognitive performance.

Patterns of Thought: Mapping Memory Management Strategies
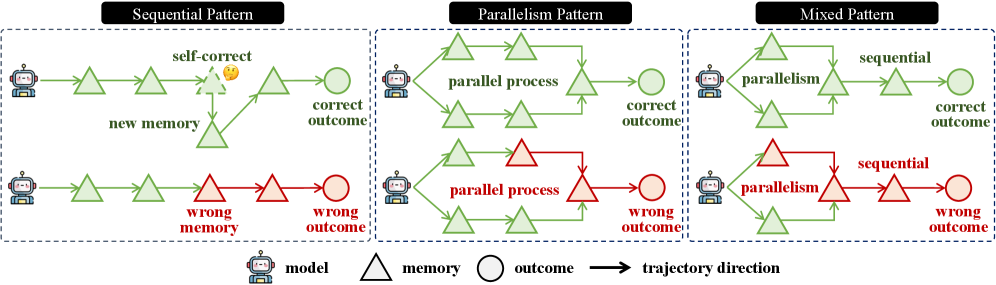
Various memory management patterns are employed in sequence processing, each characterized by distinct performance trade-offs. Sequential patterns process data in a linear fashion, prioritizing order and predictability, but potentially limiting throughput. Parallel patterns, conversely, leverage concurrent processing to accelerate operations, though this can introduce complexities in maintaining data consistency and may require substantial computational resources. Other patterns, such as those utilizing attention mechanisms or hierarchical structures, represent further variations designed to address specific challenges inherent in handling extended sequences. The optimal choice of pattern depends heavily on the specific application requirements, including sequence length, processing speed demands, and acceptable levels of error.
The Sequential Memory Pattern operates by processing input data in a strict linear order, evaluating each element before moving to the next. This approach is particularly well-suited for tasks where the order of information is critical to the outcome, such as time-series analysis or natural language processing requiring contextual understanding. However, the inherently serial nature of this pattern limits its processing speed, as each step must complete before the next can begin, resulting in increased latency when handling large datasets or complex sequences. This contrasts with parallel processing methods which can evaluate multiple elements concurrently, though potentially at the cost of maintaining strict order.
The Parallelism Memory Pattern functions by processing multiple pieces of information simultaneously, thereby reducing the overall time required for sequence analysis. This is achieved through the division of the input sequence into independent segments, each processed by a dedicated computational unit. While this concurrent approach enhances processing speed, it introduces potential challenges related to maintaining coherence and contextual understanding across the entire sequence. Specifically, dependencies between segments, if not explicitly managed, can lead to inconsistencies or inaccuracies in the final output, necessitating additional mechanisms for synchronization and data reconciliation.
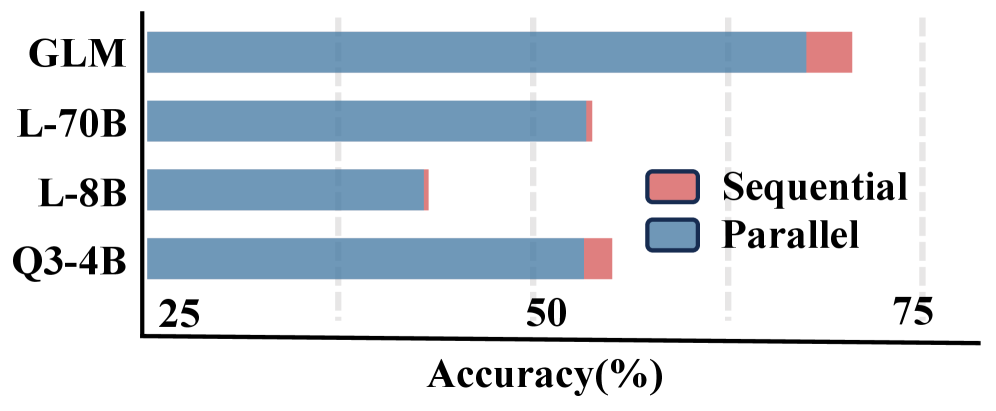
Mixed Memory Patterns represent a design approach aiming to leverage the advantages of both sequential and parallel information processing. These hybrid systems attempt to achieve speed improvements through parallel operations while retaining the accuracy associated with ordered, step-by-step sequential processing. Current evaluations, using existing Reward Models, indicate that sequential processing patterns consistently demonstrate higher accuracy rates compared to parallel patterns. This suggests that current reward mechanisms may be more readily able to assess and validate the outputs of sequentially processed information, potentially due to a more predictable and interpretable processing chain.
Architectures of Recall: A-Mem and Mem0 for Enhanced Memory
A-Mem and similar architectures improve memory retrieval efficiency by associating data updates with semantic tags. These tags function as metadata, providing contextual information about the nature and relevance of each memory element. Instead of relying solely on address-based access, the system utilizes these tags to filter and prioritize search results, enabling more targeted and efficient access to relevant information. This annotation process creates a richer representation of each memory update, allowing the system to discern the meaning and significance of data beyond its raw value, ultimately reducing search latency and improving overall performance when retrieving information from long sequences.
Mem0 operates by maintaining a continuously updated global memory summary, a condensed representation of the system’s current knowledge. This summary is modified with each processing step to reflect new information and changes in state. The core benefit of this approach is the ability to rapidly assess the relevance of incoming data against the existing global context, thereby minimizing redundant computations. By referencing the summary, the system can efficiently identify and access key information without needing to scan the entire memory, significantly improving processing speed and reducing computational cost, particularly when dealing with extended sequences or complex data.
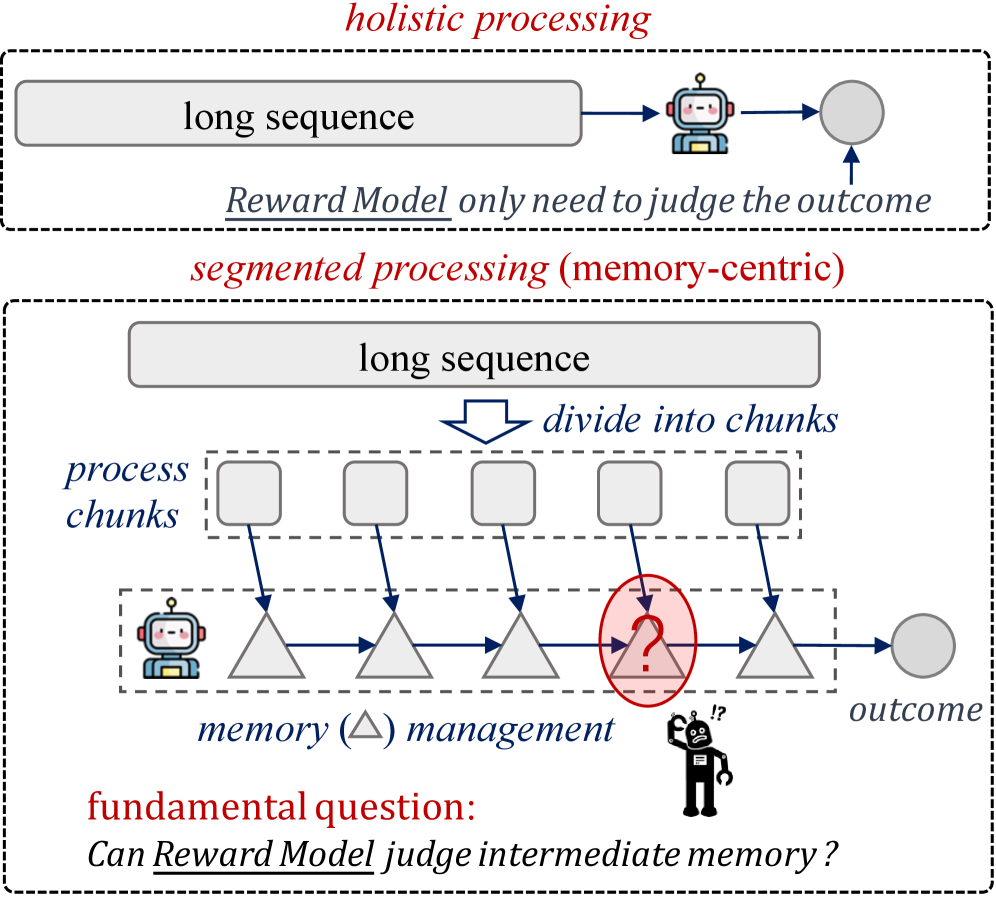
Segmented Processing and Holistic Processing represent distinct approaches to managing long sequence data alongside advanced memory architectures like A-Mem and Mem0. Segmented Processing divides the input sequence into smaller, manageable segments, processing each independently before integrating the results; this reduces computational load but may lose contextual information. Conversely, Holistic Processing aims to consider the entire sequence simultaneously, preserving long-range dependencies but demanding significantly greater resources. The choice between these methods, and their integration with architectures designed for contextual awareness, directly impacts the efficiency and accuracy of processing extended data streams, influencing both computational cost and the quality of derived information.
Optimizing long-term memory performance necessitates the implementation of advanced memory architectures like A-Mem and Mem0, as well as processing techniques such as Segmented and Holistic Processing. These approaches address limitations in traditional sequential processing of extended data sequences, which often result in performance bottlenecks and information loss. By incorporating semantic annotations, global memory summaries, and strategically dividing or considering entire input contexts, these methods reduce redundant computations and enhance the retrieval of relevant information over extended time horizons. The effective integration of these innovations is crucial for applications requiring sustained performance with large datasets, including natural language processing, time-series analysis, and complex reasoning systems.
Measuring Memory: The MemRewardBench Evaluation Framework
MemRewardBench is a newly developed benchmark specifically designed to quantify the effectiveness of reward models in evaluating long-term intermediate memories within Large Language Models (LLMs). Unlike traditional benchmarks focused solely on final output, MemRewardBench assesses the quality of memories generated and retained during the LLM’s reasoning process. This is achieved by leveraging principles of reward modeling, allowing for granular feedback on the relevance, consistency, and utility of these intermediate memories. The benchmark’s methodology centers on evaluating how well the reward model can discern between helpful and detrimental memories when applied to long-context reasoning tasks, thereby providing a focused metric for advancements in LLM memory management architectures.
MemRewardBench utilizes principles from Reward Modeling (RM) to assess the quality of long-term memory in Large Language Models (LLMs). This is achieved through two primary RM approaches: Discriminative Rewards, which directly score the relevance and accuracy of retrieved memories, and Generative Reward Models, which evaluate memories based on their ability to inform and improve subsequent LLM outputs. Discriminative rewards provide a direct assessment of memory content, while generative rewards focus on the utility of the memory in a dynamic context, allowing for a more nuanced understanding of memory effectiveness beyond simple recall accuracy. This combined approach enables a detailed evaluation of how well LLMs manage and utilize their long-term memories.
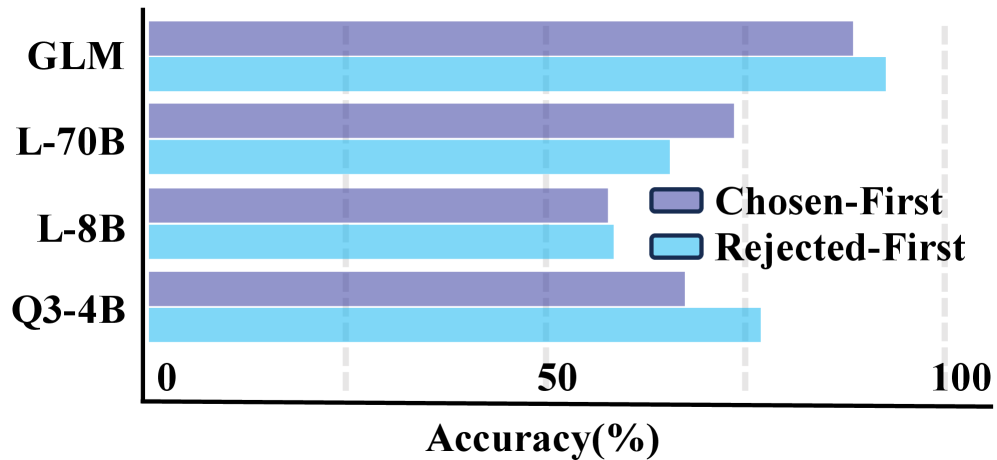
MemRewardBench utilizes two distinct evaluation methodologies to assess LLM memory management. Outcome-Based Evaluation focuses on the final result of a task, determining if the LLM successfully retrieved and applied relevant information from its memory to achieve the desired outcome. Process-Based Evaluation, conversely, examines the steps taken by the LLM during task completion, analyzing the quality and relevance of information accessed from memory at each stage. This dual approach provides a more complete understanding of memory performance, differentiating between successful outcomes achieved through potentially flawed memory access and genuinely effective long-term memory management strategies.
Evaluation using MemRewardBench has yielded quantifiable results demonstrating its capacity for discerning performance in long-context reasoning. Specifically, Claude-Opus-4.5 achieved an accuracy of 74.75% on tasks designed to assess memory management capabilities. Furthermore, GLM-4.5-106A12B outperformed Qwen3-Max, achieving a score of 68.21% under the same evaluation conditions, indicating the benchmark’s sensitivity in differentiating between model architectures and their effectiveness in utilizing long-term memory.
A standardized and rigorous evaluation framework, such as MemRewardBench, is essential for accelerating development in large language model (LLM) memory management. Currently, progress is hampered by a lack of consistent metrics for assessing the quality and efficacy of long-context reasoning and memory architectures. Systematic benchmarking allows researchers to quantitatively compare different memory mechanisms – including retrieval-augmented generation and attention modifications – and identify those that demonstrably improve performance on complex tasks. This data-driven approach facilitates targeted innovation and enables the efficient allocation of resources towards the most promising architectural designs, ultimately leading to more capable and reliable LLMs.
Beyond Scale: Charting the Future of Long-Context LLMs
The pursuit of increasingly capable long-context Large Language Models (LLMs) necessitates ongoing innovation in both model architecture and evaluation methodologies. Current LLMs often struggle to reliably access and utilize information dispersed across extensive input sequences; therefore, researchers are actively exploring novel memory architectures – moving beyond simple attention mechanisms to incorporate techniques like hierarchical memory, recurrent memory networks, and external knowledge retrieval. Crucially, progress in these areas is inextricably linked to the development of robust evaluation benchmarks; existing metrics frequently fail to adequately capture the nuances of long-context performance, necessitating the creation of datasets and protocols that rigorously assess a model’s ability to maintain coherence, avoid information loss, and accurately synthesize information across lengthy inputs. This iterative process of architectural refinement and benchmark development is paramount to building LLMs capable of genuinely leveraging the power of long-context understanding.
Leveraging the insights gleaned from MemRewardBench offers a promising pathway toward significantly enhancing the memory management capabilities of large language models. This benchmark, designed to rigorously evaluate long-context handling, provides a quantifiable reward signal that can be directly integrated into model training pipelines. By rewarding models for effectively utilizing and retrieving information from extended contexts, researchers can incentivize the development of architectures that prioritize relevant data retention and minimize information loss. This approach moves beyond simply increasing model size, instead focusing on optimizing how information is stored and accessed, ultimately leading to LLMs capable of maintaining coherence and accuracy across substantially longer sequences and complex reasoning tasks. The refinement of memory mechanisms through this feedback loop promises a new generation of LLMs with demonstrably superior long-term memory and contextual understanding.
Recent advancements in large language models (LLMs) reveal a compelling trend: each successive generation consistently surpasses the performance of its predecessors, even when controlling for the number of parameters. This isn’t simply a matter of scale; architectural innovations and refined training methodologies are proving more impactful than sheer size. Studies indicate that newer models exhibit improved efficiency in processing and retaining information from extended contexts, achieving higher accuracy and coherence in tasks demanding long-range dependencies. This progress suggests that the field is moving beyond simply increasing model capacity and towards developing more intelligent and resourceful architectures, hinting at a future where LLMs can effectively navigate and utilize vastly larger knowledge bases without a proportional increase in computational cost.
The true potential of advancements in long-context language models lies in their application to increasingly complex cognitive tasks, particularly Long-Context Reasoning. This involves not merely processing extensive information, but synthesizing it to draw nuanced conclusions and solve problems requiring deep understanding. Successfully implementing these techniques promises to revolutionize information retrieval, moving beyond simple keyword searches to semantic understanding and contextual relevance. Moreover, it could dramatically accelerate knowledge discovery by enabling models to identify previously unseen connections and patterns within vast datasets, fostering innovation across scientific disciplines and beyond. The ability to reason effectively with extensive context represents a pivotal step towards creating artificial intelligence capable of genuine insight and discovery.
The realization of truly intelligent large language models hinges decisively on advancements in long-term memory management. Current models, while impressive in their abilities, often struggle with maintaining coherence and accessing relevant information across extended contexts, limiting their potential for complex reasoning and nuanced understanding. Effectively managing this “long context” isn’t simply about increasing the window of information a model can process; it requires innovative architectures and training methodologies that allow for efficient storage, retrieval, and utilization of knowledge over prolonged interactions. Such mastery would enable LLMs to move beyond pattern recognition and towards genuine comprehension, facilitating breakthroughs in areas demanding sustained cognitive effort – from in-depth scientific inquiry and intricate narrative generation to personalized education and proactive problem-solving – ultimately bridging the gap between artificial intelligence and true cognitive capability.
The pursuit of robust long-term memory in large language models necessitates rigorous evaluation of reward model efficacy. This work, introducing MemRewardBench, highlights a crucial deficiency: current reward models struggle to accurately assess the quality of memory management over extended contexts. As Barbara Liskov observed, “Programs must be correct, but they must also be understandable.” The benchmark serves as a clarifying instrument, exposing the limitations of existing reward mechanisms and providing a framework for developing more discerning models. The core concept of evaluating memory recall isn’t simply about accuracy, but about structuring information for accessibility – a principle of understandable design mirrored in Liskov’s statement. It is not enough for a model to store information; it must retrieve and utilize it effectively, and reward models must accurately reflect this capacity.
Future Directions
The introduction of MemRewardBench exposes, with necessary precision, the current inadequacy of reward models in discerning effective long-term memory management. The observed limitations are not failings of implementation, but rather symptomatic of a deeper issue: the conflation of surface-level coherence with genuine contextual recall. Current metrics prioritize immediate relevance, a computationally cheap heuristic that masks the erosion of factual consistency over extended interactions. Unnecessary is violence against attention; future work must prioritize metrics that penalize subtle, long-term drifts from ground truth.
The path forward necessitates a shift from evaluating what is remembered, to evaluating how it is remembered. Reward models require refinement to assess the structure and integrity of the memory itself – not merely the accessibility of information. Density of meaning is the new minimalism. Evaluating memory organization, resistance to interference, and the ability to synthesize novel insights from recalled data represents a more rigorous, and ultimately more useful, challenge.
Ultimately, this work suggests that the true benchmark lies not in creating larger context windows, but in developing more discerning evaluators. The pursuit of long-term memory in large language models is, at its core, a problem of information fidelity. The focus must therefore shift from quantity to quality, from recall to reliable recall.
Original article: https://arxiv.org/pdf/2601.11969.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Super Mario Galaxy Movie: 50 Easter Eggs, References & Major Cameos Explained
- Surprise Isekai Anime Confirms Season 2 With New Crunchyroll Streaming Release
- 10 Best Free Games on Steam in 2026, Ranked
- Sydney Sweeney’s The Housemaid 2 Sets Streaming Release Date
- ‘Project Hail Mary’: The Biggest Differences From the Book, Explained
- Starfield (PS5) Review – A Successful Cross-Console Voyage
- Skate 4 – Manny Go Round Goals Guide | All of the Above Sequence
- All 7 New Supes In The Boys Season 5 & Their Powers Explained
- Preview: Sword Art Online Returns to PS5 as a Darker Open World Action RPG This Summer
- Frieren: Beyond Journey’s End Gets a New Release After Season 2 Finale
2026-01-21 09:19